
'Story List'에 해당되는 글 171건
- 2022.08.13 :: [데이타 변환] list str 원소를 int 로 변환
- 2022.08.10 :: [Pandas] 데이타프레임(DataFrame)을 엑셀(excel) 파일로 저장
- 2022.07.01 :: [Anaconda] 가상환경(virtual environment) 관리
- 2022.06.05 :: [Python] 집합(set) 객체 정리
- 2022.05.31 :: [Python] 튜플(tuple) 객체 정리
- 2022.05.27 :: [Python] 시퀀스 자료형[Sequence types]
- 2022.05.24 :: [C/C++] excel library 추천
- 2022.05.23 :: [c/c++] 생성자 vs 복사생성자 vs 대입 대입 연산자
- 2022.05.23 :: [Python] Object 비교
- 2022.05.20 :: [Python] 객체 종류(mutable,immutable) vs 메모리(memory)
파이썬의 데이타 변환은 이전 블로그 글에서 소개드린 대로 매우 직관적으로 됩니다. 하지만, 다른 객체의 원소로 포함된 데이타 타입의 변환은 익숙하지 않으면 실수할 수 있어 정리하고자 합니다.
# List 원소 str원소를 int로 변환
stringList = ['1','2','3','4','5']
print(type(stringList))
print(stringList)
# 방법1: map 사용
intList1 = list(map(int,stringList))
print(type(intList1))
print(intList1)
# 방법2: list 사용
intList2 = [int(n) for n in stringList]
print(type(intList2))
print(intList2)[결과]
['1', '2', '3', '4', '5']
<class 'list'>
[1, 2, 3, 4, 5]
<class 'list'>
[1, 2, 3, 4, 5]
cf) 추가 적으로 위의 방법은 python 3인 경우에 적용되며, python 2를 사용한다면 아래를 사용
intList1 = map(int, stringList)
print(type(intList1))
print(intList1)DataFrame 데이터를 엑셀(excel)로 저장하는 방법중 개인적으로 선호하는 두가지 방법을 정리하고자 합니다.
1. to_excel() 사용
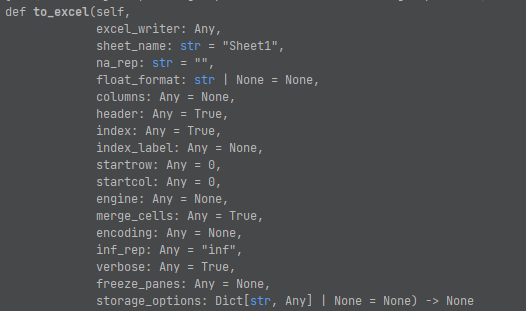
to_excel()함수를 보면, 다양한 인자를 지원하고 있는 것을 확인 할수 있습니다. 하나하나 세세하게 살표보면 좋겠지만, 제 경험상으로는 파일 이름(excel_writer)과 엑셀형식에서 맞게 시트 이름(sheet_name) 정도만 알면 일차적으로 접근하는데는 무리가 없습니다.
(샘플코드)
# 투자자별 순매수 상위종목
# 20220808 부터 20220809 까지 개인의 순매수 금액이 높은 순서대로 종목을 정렬해서 반환
# KOSPI, KOSDAQ, KONEX
# 금융투자 / 보험 / 투신 / 사모 / 은행 / 기타금융 / 연기금 / 기관합계 / 기타법인 / 개인 / 외국인 / 기타외국인 / 전체
market = "ALL"
strfrom = "20220809"
strTo = "20220809"
foreignDf = stock.get_market_net_purchases_of_equities(strfrom, strTo, market, "외국인")
print(foreignDf)
# 파일 이름
prefix = 'cww'
suffix = datetime.datetime.now().strftime("_%y%m%d_%H%M%S.xlsx") #연월일_시분초
print('{}{}'.format(prefix,suffix))
filename = prefix + suffix
print(filename)
# 저장
foreignDf.to_excel(
excel_writer=filename,
sheet_name='외국인',
index=False)
print('Done')위의 코드는 프로젝트 코드의 일부를 발취한 부분으로, 주기적으로 외국인이 순매수한 거래량과 거래대금등을 취합하고, 그 내용을 엑셀 파일로 기록하는 부분입니다.
해당 경로에 파일이 파일이 없으면 새로 만들지만, 이미 존재하면 덮어쓰기를 함
(실행결과)

to_excel()의 경우 하나의 시트만 저장 가능함. (이 부분은 단점으로 생각됨)
그래서, 하나의 엑셀파일에 여러 시트를 저장하는 경우는 아래의 방법을 사용
2. ExcelWriter()사용
여러개 데이타프레임을 하나의 엑셀 파일에 저장
# 투자자별 순매수 상위종목
# 20220808 부터 20220809 까지 개인의 순매수 금액이 높은 순서대로 종목을 정렬해서 반환
# KOSPI, KOSDAQ, KONEX
# 금융투자 / 보험 / 투신 / 사모 / 은행 / 기타금융 / 연기금 / 기관합계 / 기타법인 / 개인 / 외국인 / 기타외국인 / 전체
market = "ALL"
strfrom = "20220809"
strTo = "20220809"
foreignDf = stock.get_market_net_purchases_of_equities(strfrom, strTo, market, "외국인")
print(foreignDf)
#market = "KOSPI"
gigwanDf = stock.get_market_net_purchases_of_equities(strfrom, strTo, market, "기관합계")
print(gigwanDf)
#
tusinDf = stock.get_market_net_purchases_of_equities(strfrom, strTo, market, "투신")
print(tusinDf)
#
samoDf = stock.get_market_net_purchases_of_equities(strfrom, strTo, market, "투신")
print(samoDf)
# 파일 이름
prefix = 'cww'
suffix = datetime.datetime.now().strftime("_%y%m%d_%H%M%S.xlsx") #연월일_시분초
print('{}{}'.format(prefix,suffix))
filename = prefix + suffix
print(filename)
# 저장
writer = pd.ExcelWriter(filename)
foreignDf.to_excel(writer, sheet_name='외국인')
gigwanDf.to_excel(writer, sheet_name='기관')
tusinDf.to_excel(writer, sheet_name='투신')
samoDf.to_excel(writer, sheet_name='사모')
writer.save()(출력결과)

가상환경을 제공하는 아나콘다(Anaconda)에서 필수적인 명령어를 정리하고자 합니다.
1) 버전 확인
[Anaconda Prompt(anaconda3)]
(base) D:\NextTime\cwwDev>conda -V
conda 4.13.0
2) 라이브러리(패키지) 설치, 업데이트 그리고 삭제하기
2-1) 설치된 라이브러리(패키지) 전체 업데이트
(base) D:\NextTime\cwwDev>conda update --all
Collecting package metadata (current_repodata.json): done
Solving environment: done
# All requested packages already installed.
2-2) 라이브러리(패키지) 설치
(base) D:\NextTime\cwwDev>conda install 라이브러리(패키지)명
2-3) 부분 업데이트
(base) D:\NextTime\cwwDev>conda update 라이브러리(패키지)명
2-4) 라이브러리(패키지) 삭제
(base) D:\NextTime\cwwDev>conda remove 라이브러리(패키지)명
3) 설치된 가상환경(virtual environment) 확인
(base) D:\NextTime\cwwDev>conda info --env
# conda environments:
#
base * d:\Dev\anaconda3 <-- 기본 아나콘다 가상환경
(base) D:\NextTime\cwwDev>conda env list
# conda environments:
#
base * d:\Dev\anaconda3 <-- 기본 아나콘다 가상환경
4) 사용중인 가상환경에 구성된 시스템 정보보기
4-1) 64 bit 확인
(base) D:\NextTime\cwwDev>conda info
active environment : base
active env location : d:\Dev\anaconda3
shell level : 1
user config file : C:\Users\CHOI\.condarc
populated config files : C:\Users\CHOI\.condarc
conda version : 4.13.0
conda-build version : 3.21.9
python version : 3.8.5.final.0
virtual packages : __cuda=11.1=0
__win=0=0
__archspec=1=x86_64
base environment : d:\Dev\anaconda3 (writable)
conda av data dir : d:\Dev\anaconda3\etc\conda
conda av metadata url : None
channel URLs : https://repo.anaconda.com/pkgs/main/win-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/win-64
https://repo.anaconda.com/pkgs/r/noarch
https://repo.anaconda.com/pkgs/msys2/win-64
https://repo.anaconda.com/pkgs/msys2/noarch
package cache : d:\Dev\anaconda3\pkgs
C:\Users\CHOI\.conda\pkgs
C:\Users\CHOI\AppData\Local\conda\conda\pkgs
envs directories : d:\Dev\anaconda3\envs
C:\Users\CHOI\.conda\envs
C:\Users\CHOI\AppData\Local\conda\conda\envs
platform : win-64
user-agent : conda/4.13.0 requests/2.24.0 CPython/3.8.5 Windows/10 Windows/10.0.19041
administrator : False
netrc file : None
offline mode : False
4-2) 32 bit 확인
(base) D:\NextTime\cwwDev>set CONDA_FORCE_32BIT=1
(base) D:\NextTime\cwwDev>conda info
active environment : base
active env location : d:\Dev\anaconda3
shell level : 1
user config file : C:\Users\CHOI\.condarc
populated config files : C:\Users\CHOI\.condarc
conda version : 4.13.0
conda-build version : 3.21.9
python version : 3.8.5.final.0
virtual packages : __cuda=11.1=0
__win=0=0
__archspec=1=x86
base environment : d:\Dev\anaconda3 (writable)
conda av data dir : d:\Dev\anaconda3\etc\conda
conda av metadata url : None
channel URLs : https://repo.anaconda.com/pkgs/main/win-32
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/win-32
https://repo.anaconda.com/pkgs/r/noarch
https://repo.anaconda.com/pkgs/msys2/win-32
https://repo.anaconda.com/pkgs/msys2/noarch
package cache : d:\Dev\anaconda3\pkgs32
C:\Users\CHOI\.conda\pkgs32
C:\Users\CHOI\AppData\Local\conda\conda\pkgs32
envs directories : d:\Dev\anaconda3\envs
C:\Users\CHOI\.conda\envs
C:\Users\CHOI\AppData\Local\conda\conda\envs
platform : win-32
user-agent : conda/4.13.0 requests/2.24.0 CPython/3.8.5 Windows/10 Windows/10.0.19041
administrator : False
netrc file : None
offline mode : False
5) 가상환경(virtual environment) 만들기
(base) D:\NextTime\cwwDev>conda create -n py39_32 python=3.9
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: d:\Dev\anaconda3\envs\py39_32
added / updated specs:
- python=3.9
The following packages will be downloaded:
package | build
---------------------------|-----------------
ca-certificates-2022.4.26 | haa95532_0 124 KB
certifi-2022.6.15 | py39haa95532_0 153 KB
openssl-1.1.1p | h2bbff1b_0 4.8 MB
pip-21.2.4 | py39haa95532_0 1.8 MB
python-3.9.12 | h6244533_0 17.1 MB
setuptools-61.2.0 | py39haa95532_0 1.0 MB
sqlite-3.38.5 | h2bbff1b_0 798 KB
tzdata-2022a | hda174b7_0 109 KB
vc-14.2 | h21ff451_1 8 KB
vs2015_runtime-14.27.29016 | h5e58377_2 1007 KB
wheel-0.37.1 | pyhd3eb1b0_0 33 KB
wincertstore-0.2 | py39haa95532_2 15 KB
------------------------------------------------------------
Total: 26.9 MB
The following NEW packages will be INSTALLED:
ca-certificates pkgs/main/win-64::ca-certificates-2022.4.26-haa95532_0
certifi pkgs/main/win-64::certifi-2022.6.15-py39haa95532_0
openssl pkgs/main/win-64::openssl-1.1.1p-h2bbff1b_0
pip pkgs/main/win-64::pip-21.2.4-py39haa95532_0
python pkgs/main/win-64::python-3.9.12-h6244533_0
setuptools pkgs/main/win-64::setuptools-61.2.0-py39haa95532_0
sqlite pkgs/main/win-64::sqlite-3.38.5-h2bbff1b_0
tzdata pkgs/main/noarch::tzdata-2022a-hda174b7_0
vc pkgs/main/win-64::vc-14.2-h21ff451_1
vs2015_runtime pkgs/main/win-64::vs2015_runtime-14.27.29016-h5e58377_2
wheel pkgs/main/noarch::wheel-0.37.1-pyhd3eb1b0_0
wincertstore pkgs/main/win-64::wincertstore-0.2-py39haa95532_2
Proceed ([y]/n)?y
....
done
#
# To activate this environment, use
#
# $ conda activate py39_32
#
# To deactivate an active environment, use
#
# $ conda deactivate
(base) D:\NextTime\cwwDev>
(base) D:\NextTime\cwwDev>conda env list
# conda environments:
#
base * d:\Dev\anaconda3
py39_32 d:\Dev\anaconda3\envs\py39_32
5) 가상환경(virtual environment) 지우기
(base) D:\NextTime\cwwDev>conda env remove -n py39_32
Remove all packages in environment d:\Dev\anaconda3\envs\py39_32:
(base) D:\NextTime\cwwDev>conda env list
# conda environments:
#
base * d:\Dev\anaconda3
6) 생성된 가상환경(virtual environment) 활성화 및 비활성화
6-1) 활성화
(base) D:\NextTime\cwwDev>conda activate py39_32
(py39_32) D:\NextTime\cwwDev>
6-2) 비활성화
(py39_32) D:\NextTime\cwwDev>conda deactivate
(base) D:\NextTime\cwwDev>
7) 생성된 가상환경(virtual environment)에 패키지 설치
7-1) 가상환경(virtual environment) 생성, 진입(활성화), 그리고 설치하기
(base) D:\NextTime\cwwDev>conda activate py39_32
(py39_32) D:\NextTime\cwwDev>pip install pyqt5
(py39_32) D:\NextTime\cwwDev>pip install pykiwoom
7-2) 가상환경(virtual environment) 생성하면서 동시에 패키지 설치하기
(base) D:\NextTime\cwwDev>conda create -n py39_32 python=3.9 pyqt5 pykiwoom
Python 언어가 다른 개발언어와 비교할때, 가장 개성(?)있는 장점이 집합(set)객체의 제공이라고 생각합니다.
데이타의 집합을 직관적으로 합집합, 차집합, 교집합으로 처리할때 마치 SQL 언어에서 사용할때 보다 더욱 편리하게 느껴집니다. 개인적으로, 이 특성으로 인해 Python이 데이타 처리에 큰 강점을 가지게 된것 같습니다.
(또한, 이전에는 Database에 데이타를 넣고, 프로시져를 통해서 처리하던 부분을 지금은 다르게 처리하게 되었습니다.)
집합(set) 객체를 한마리도 정리하면 '중복이 허용되지 않는 mutable type의 객체라고 정의 합니다.
백문이 불여 일타록 하였으니 정리된 코드로 확인해보도록 하겠습니다.
#########################################
# [집한(set) 실습]
# 1) 정의: 중복이 허용되지 않는 mutable data object이다.
# 2) 접근: NOT Sequence type
# 3) 집합 기능: 합집합, 교집한, 차집합
# 4) 추가적인 함수: 넣고, 빼기, 업데이트하기
###### 1) 정의
aSet1 = set()
print(aSet1)
print(type(aSet1))
aSet2 = set((1,2,3,4,5)) # 튜플(tuple) -> 집합(set)
print(aSet2)
aSet3 = set(['a', 'b', 'c', 'd', 'e']) # 리스트(list) -> 집합(set)
print(aSet3)
aSet4 = set('Hello world') # 문자열(string) -> 집합(set)
print(aSet4) # 데이타 중복 제거[결과]
set()
<class 'set'>
{1, 2, 3, 4, 5}
{'b', 'a', 'd', 'c', 'e'}
{'l', 'w', 'd', ' ', 'r', 'H', 'o', 'e'}
# 2) 접근: Sequence type 아니기 때문애 indexing 접근불가
# indexing을 하기 위해서는 Sequence type으로 전환(convert) 필요
aList2 = list(aSet2) # tuple -> set -> list
print(aList2)
print(aList2[2])
aTuple3 = tuple(aSet3) # list -> set -> tuple
print(aTuple3)
print(aTuple3[0])
aStr3 = str(aSet4) # string -> set -> string
print(aStr3)
print(aStr3[1])
[결과]
[1, 2, 3, 4, 5]
3
('b', 'a', 'd', 'c', 'e')
b
{'l', 'w', 'd', ' ', 'r', 'H', 'o', 'e'}
'
# 3) 집합 기능: 합집합, 교집한, 차집합
bSet = set([1,2,3,4,5,6,7]) # list -> set
cSet = set((4,5,6,7,8,9)) # tuple -> set
print(bSet)
print(cSet)
# 차집합 : '-', difference()
dSetDiff1 = bSet - cSet
print(dSetDiff1)
dSetDiff2 = bSet.difference(cSet)
print(dSetDiff2)
# 교집합 : '&', intersection()
dSetInter1 = bSet & cSet
print(dSetInter1)
dSetInter2 = bSet.intersection(cSet)
print(dSetInter2)
# 합집합: '|', union()
dSetUnion1 = bSet | cSet
print(dSetUnion1)
dSetUnion2 = bSet.union(cSet)
print(dSetUnion2)[결과]
{1, 2, 3, 4, 5, 6, 7}
{4, 5, 6, 7, 8, 9}
{1, 2, 3}
{1, 2, 3}
{4, 5, 6, 7}
{4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7, 8, 9}
{1, 2, 3, 4, 5, 6, 7, 8, 9}
# 추가적인 함수
fSet = set(['a','b','c','d'])
print(fSet)
# 추가: add()
fSet.add(1)
print(fSet)
# 업데이트: update()
fSet.add((3,4,5))
print(fSet)
# 삭제: remove()
fSet.remove(1)
print(fSet)
[결과]
{'c', 'b', 'a', 'd'}
{1, 'b', 'a', 'd', 'c'}
{1, 'b', 'a', 'd', (3, 4, 5), 'c'}
{'b', 'a', 'd', (3, 4, 5), 'c'}
튜플(tuple)을 간단히 말하면 변경할수 없는(immutable) 시퀀스 자료형(sequence type)입니다.
그런데, 앞에서 학습한 리스트(list)가 있는데 왜? 튜플(tuple)이 있을까?
그 이유는, 튜플은 리스트에 비해서, 가볍고(즉, 빠르다)고 메모리를 작게 사용합니다.(이 부분은 별도로 정리하겠습니다.)
튜플(tuple) 사용 용례를 정리하면 다음과 같습니다.
#########################################
# [튜플(Tuple) 실습]
# 1) sequence types 실습: indexing, slicing, concatenating, iterating, size
# 2) 왜? Tuple을 사용할까? 리스트로 다하면 되는데?
# -> 메모리를 절약하고, 성능이 더 좋다.
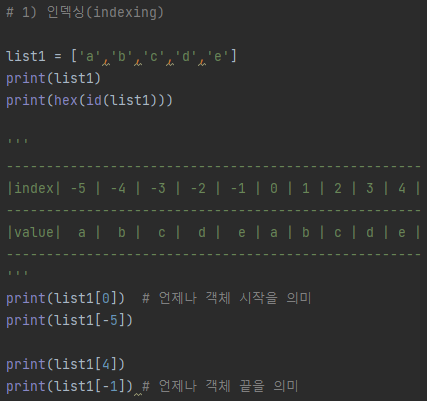
###### 1) 인덱싱(indexing)
print(aTuple)
print(aTuple[0]) # 0 인덱스: Tuple 객체의 맨 처음
print(aTuple[-1]) # -1 인덱스: Tuple 객체의 맨 마지막
# tuple안의 tuple: 기준값을 저장할때 많이 사용
dTuple = ( (1,2,3), ('a','b','c'))
print(dTuple)
print(dTuple[0])
print(dTuple[1])
print(dTuple[0][1])
print(dTuple[1][0])[결과]
(1, 2, 3, 4, 5, 6, 7, 8, 9)
1
9
((1, 2, 3), ('a', 'b', 'c'))
(1, 2, 3)
('a', 'b', 'c')
2
a# 2) 슬라이싱(slicing)
print(aTuple[1:]) # 인덱스 1부터 마지막까지
print(aTuple[:4]) # 인덱스 처음(0)부터 인덱스 4까지
print(aTuple[1:3]) # 인덱스 1부터 인덱스 5까지
print(aTuple[:]) # 인덱스 처음 마지막까지
print(aTuple[1:9:2]) # 인덱스 1부터, 9까지, 2간격으로 추출[결과]
(2, 3, 4, 5, 6, 7, 8, 9)
(1, 2, 3, 4)
(2, 3)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
(2, 4, 6, 8)# 3) 연결(concatenating)
bTuple = ('a','b','c','d')
cTuple = aTuple + bTuple
print(cTuple)[결과]
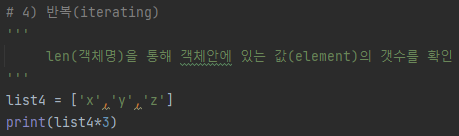
(1, 2, 3, 4, 5, 6, 7, 8, 9, 'a', 'b', 'c', 'd')# 4) 반복(iterating)
print(bTuple*3)[결과]
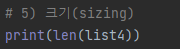
('a', 'b', 'c', 'd', 'a', 'b', 'c', 'd', 'a', 'b', 'c', 'd')# 5) 크기(sizing)
print(len(bTuple))[결과]
40. 정의
순서(번호)를 붙여 나열되어 있는 객체를 의미. 여기서 순서(번호)를 인덱스(index)라고함
각각의 요소(element) 또는 데이터(data)들이 연속적으로 이어진 자료형을 의미하며, 각, 데이터(data)에는 순서(번호)를 붙여 나열함
다시 정리하면,
시퀀스 자료형으로 만든 객체를 시퀀스 객체라고 하며 시퀀스 객체 안에 들어있는 값들을 요소라고 부릅니다.
1. 시퀀스 자료형 종류
list, tuple, 문자열, range, bytes, bytearray
2. 시퀀스 자료형 특성
1) 인덱싱 (indexing)
- 인덱스를 통해 값에 접근가능(인덱스는 0부터 시작)
2) 슬라이싱 (slicing)
- 일부분의 값을 얻을 수 있음, 원본에는 영향미치지 않음
3) 연결(concatenating)
- '+' 연산자를 통해서 두 객체를 연결해서, 새로운 시퀀스 객체를 생성
4) 반복
- '*' 연산자를 통해서 객체를 원하는 만큼 반복 가능
5) 크기
- len(객체명)을 통해 객체안에 있는 값(element)의 갯수를 확인
3. 예제







최근 트랜드는 데이타 처리 관련해서는 Python을 사용해서 작업하는 경우가 많지만, 최근 프로젝트에서 C++로 excel 파일을 사용해야 하는 경우가 있어, 몇가지 라이브러리를 테스트 진행후 개인적으로 강추하는 라이브리를 공유합니다.
https://www.libxl.com/download.html
LibXL download
LibXL for Windows 4.0.3 i386 x64 Download Date: 2022-02-01 Size: 29 679 292 bytes MD5: B42C5F0D63DF834066CA17D393468AFC LibXL for Linux 4.0.3 i386 x64 armhf Download Date: 2022-02-01 Size: 25 354 244 bytes MD5: F08C6EDB8B912A9431F271DEC3E6FD80 Li
www.libxl.com
해당 라이브러리에 익숙해지는 방법은 아래의 예제 파일을 보시면 금방입니다.
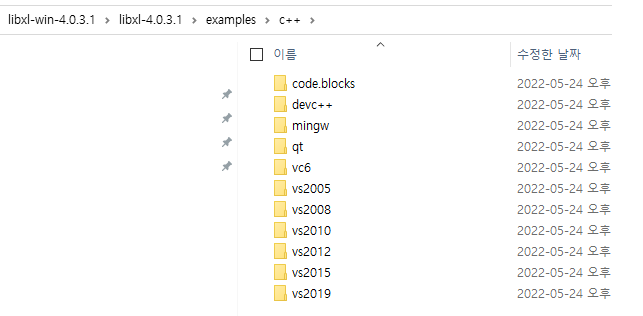
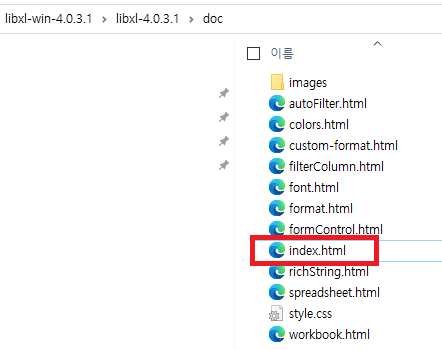
그리고, 각 API에 대한 메뉴얼은 index.html 파일을 오픈하여보시면 자세하게 나와있습니다.
개인적으로 근래 접한 오픈소스중에 가장 완성도가 높은것으로 보입니다. 각 platform , 32/64bits, 컴파일러 버젼별 지원이 어지간한 상업용 수준입니다.
감사합니다.
[기본 이론]
# 기본 개념
- 컴파일러는 클래스의 객체를 생성시 자동으로 생성자, 소멸자, 복사생성자, 복사 대입 연사자를 생성함
# (기본) 생성자란?
- 클래스(class)의 인스턴스(instance) or 객체(object)가 생성되는 시점에 자동으로 호출되는 특수한 멤버함수이다.
이 생성자 함수에서는 클래스의 멤버 변수 초기화를 담당함
# 소멸자란?
- 객체(object) 소멸시 자동으로 호출되는 함수
- 객체 메모리를 정리함
# 복사 생성자란?
- 기존에 있던 객체를 복사해서, 객체를 생성할 때 호출되는 생성자
- 자신과 같은 클래스 타입의 다른 객체에 대한 참조(reference)를 인수로 전달받아, 그 참조를 가지고 자신을 초기화
# 복사 대입 연산자라?
- 같은 타입의 객체를 이미 생성되어 있는 객체에 값을 복사할 때 호출되는 함수
# 깊은 복사(deep copy)와 얕은 복사 (shallow copy)
- 객체를 생성하고 초기화시킬 때 멤버 변수를 어떻게 초기화하느냐에 따라 깊은 복사가 될 수 있고, 얕은 복사가 될 수 있습니다.
----------------------------------------------------------------
[실무적인 정리]
지금까지는 C++을 배우면서 나오는 생성자에 관련된 이론을 정리하였습니다.
그런데, 저의 경우에 초심자일때는 어 머지(?)하는 부분이 있었습니다.
자 다시 간단히 정리하겠습니다.
복사 생성이란? 직관적으로 기존에 있던 것(객체)을 복사해서 생성하는 것이라고 정리하겠습니다.
왜? 계속 생성해서 사용하는 것보다, 이미 있는 것을 재사용하면 성능및 효율성이 좋다.
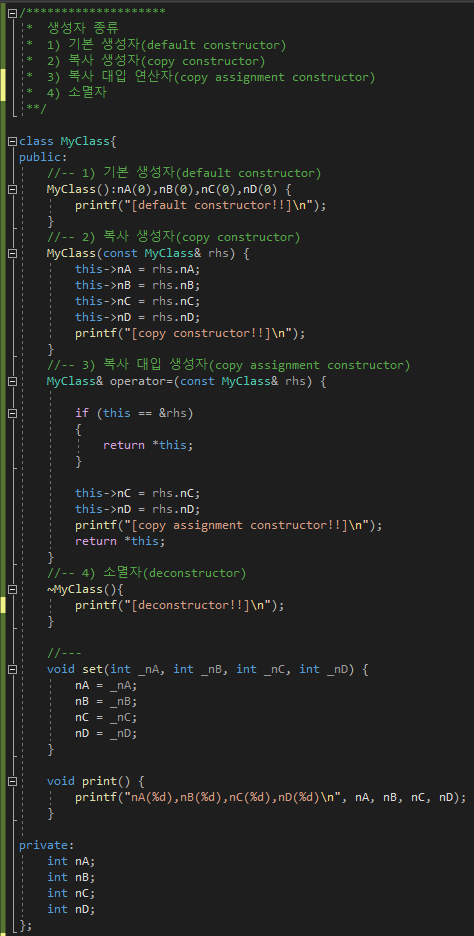
[예제1]
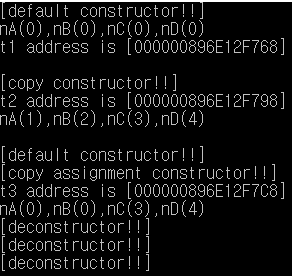
아래 코드를 보면, 복사생성자,대입연산자가 없는데??? 기능이 동작한다.
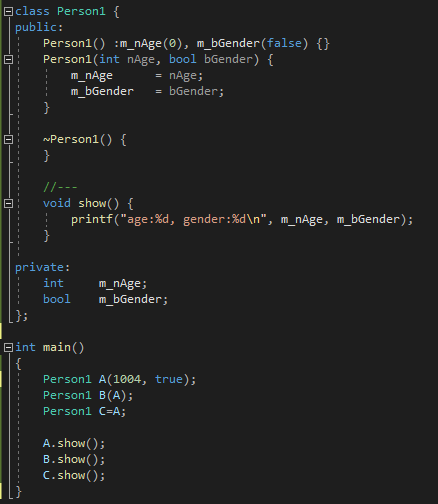
그 이유는? 컴파일러가 암묵적으로 아래의 코드에 복사생성자와 대입연산자를 생성하여 실행되기 때문입니다.
이것을 디폴트 복사생성자, 디폴트 대입연산자라고 합니다.
이렇게 컴파일러가 다해주면, 객체 복사관련하여 많은 시간을 왜 배워야 하는가??? 그것은 컴파일러가 모든것 또는 완벽
하게 개발자의 요구를 충족시켜 주지 못하기 때문입니다.(개인적인 생각)
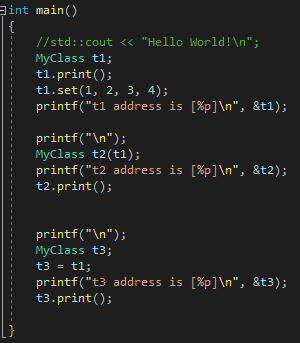
[예제2]
자 이제 공부를 해야 하는 이유를 알아 보겠습니다.
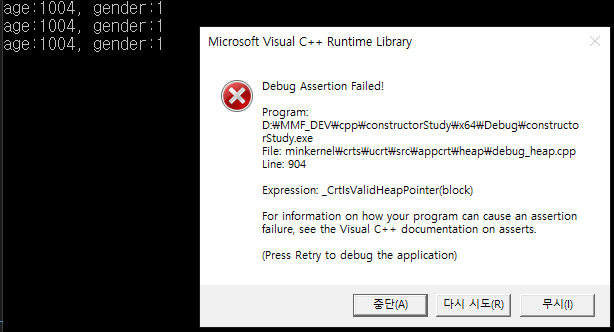
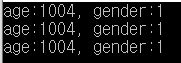
예제1과 예제2를 비교하여 보면, 차이점은 reference 멤버변수만 추가되었고, 나머지는 동일합니다.
하지만 실행을 하여 보면, 정상적으로 동작하다가 위와 같은 crash error가 발생하는 것을 확인할수 있습니다.
그 이유는 객체 복사와 대입 연사자를 통해서, reference를 새로운 객체 B와 C에 정상적으로 전달되었지만, A, B, C 객체의 소멸자중 하나라도 호출되면, 남은 두개의 객체는 reference를 잃게되기 때문입니다.
기술적으로 이러한 문제점은 얕은 복사(shallow copy)의 문제점이라고 합니다.
여기서 얕은 복사(shallow copy)에 대한 정리를 하면, "객체 복사시 변수의 메모리 reference(주소)만 복사"하는 것을 의미합니다. ( call by value, call by reference 개념 필요) 여기서 중요점은 컴파일러가 자동지원(생성)하는 복사생성자와 대입연산자는 얕은 복사(shallow copy)만 지원한다. 그리고, 이 기능은 제한 점이 있다는 것이다.
이러한 문제점을 해결하기 위해서, 개발자는 생성자에 대해서 많은 시간을 투자하게 됩니다.
그리고, 이 얕은 복사(shallow copy)의 해결책은 깊은 복사(deep copy)입니다.
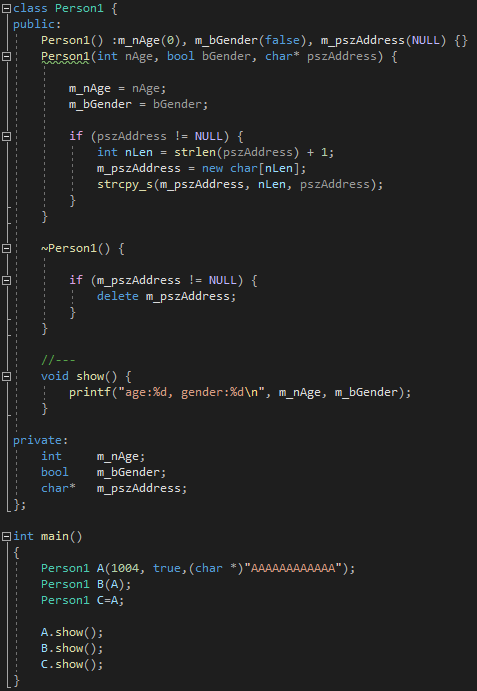
[예제3]
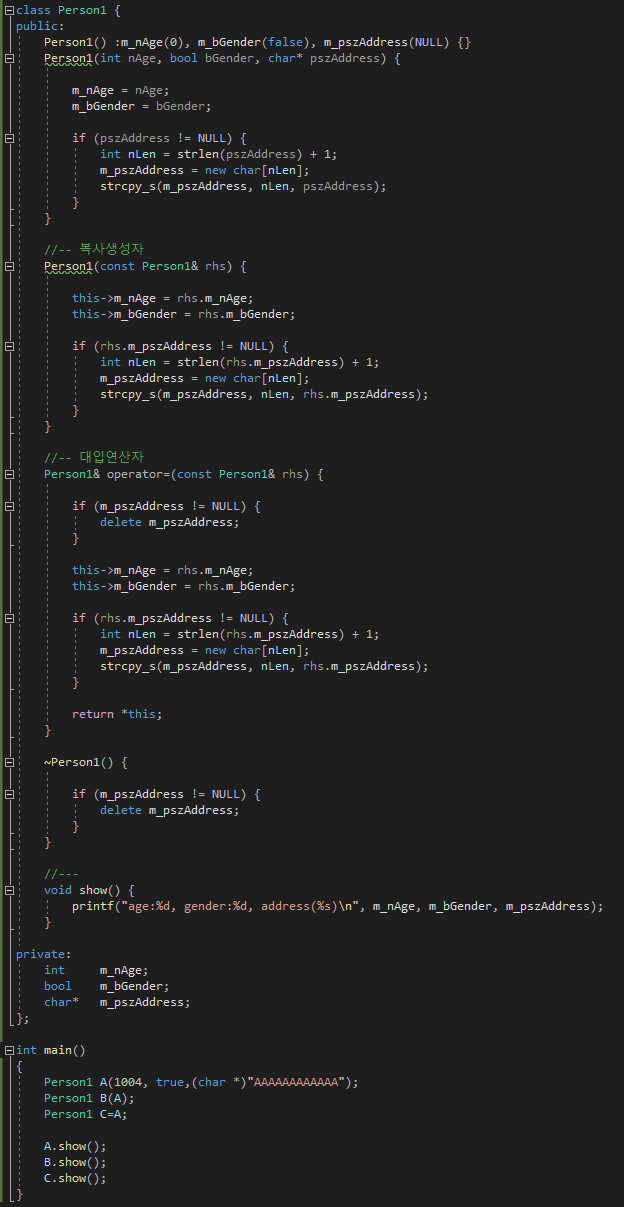

예제3 코드를 보면, 복사 생성자와 대입 연산자가 추가된것을 볼수있습니다. 그리고, 실행결과는 예제2와 다르게 에러가 발생하지 않습니다. 그리고, 그 해결책은 객체복사 reference 변수의 메모리를 새로 할당해주는 것을 깊은 복사(deep copy)라고 합니다. (참고로, 이렇게 하면 메모리와 성능은 떨어집니다.)
[개인적 생각]
솔직히 신입일때 좀 허무했던것 같습니다. 결국에는 개인적으로 c++ 오버로딩과 메모리 관리로 해결이 된 것으로 생각되었습니다. 하지만, 많은 이론을 공부했습니다. (여러종류의 생성자, 깊은복사/얕은 복사등... )
z파이썬은 모든 것이 Object이다. 그리고, Object를 비교는 2가지 관점으로 고려된다.
1) 같은 Object인가?(같은 인스턴스인가?) --> 비교연산자: is
2) Object value 값이 같은가? --> 비교연산자 ==
예제)


# 예제1 과 결과1를 보면, "is" 비교 연산자는 object의 id, 즉, memory address가 같으면 True를 반환함을 확인
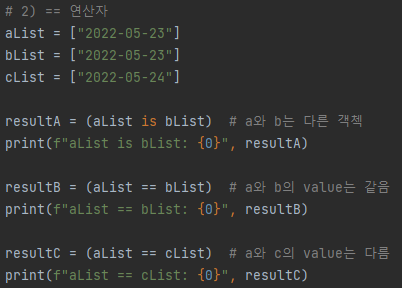
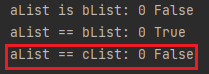
# 예제2 과 결과2를 보면, "==" 비교 연산자는 object가 가지고 있는 실제 value를 비교하여 같으면 True를 반환
# 여기서 전제조건은 같은 Data typs이여야 함
저의 경우에는 C/C++, Java 개발 언어를 선경험하고, Python을 접하게 되었을때 객체 종류(mutable,immutable)에 대한 부분은 많이 낯설게 느껴지는 부분이었습니다. 그래서, 초기에 이 부분에 많은 시간을 할애하여 공부하였습니다.
저는 아래의 두줄에 대한 내용을 간단히 정리하고자 합니다.
"파이썬의 모든것은 객체(object) 이고, 객체는 두가지(mutable vs immutable)로 분류된다.
또한, 객체는 나타내는 변수는 값(value)에 대한 참조(reference)이다."
참고로, 객체는 class라고 기능과 다양한 데이터의 조합이고, 이 클래스의 인스턴스(instance)를 객체(object)라고 합니다.
인스턴스란 class가 메모리의 영역에 할당되었다는 것을 의미함
1. 기본적인 접근
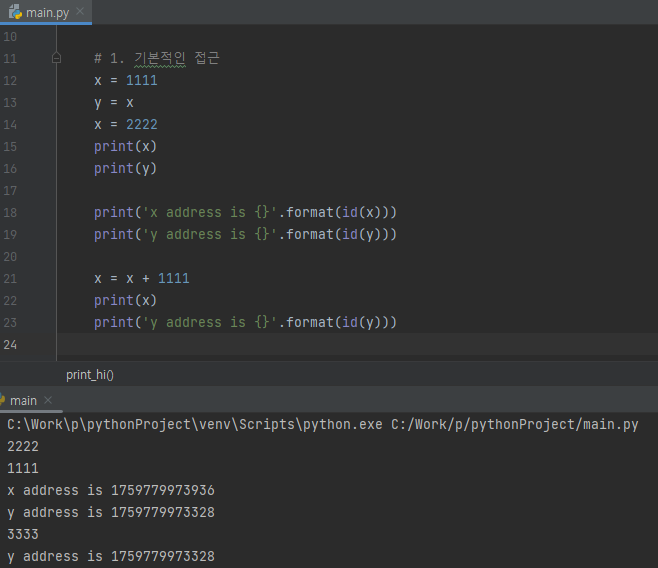
위의 예제와 실행결과를 간단히 보면, 변수 y에 변수 x값을 넣고, 변수 x의 값을 변경하였습니다. 이때, 마다 객체의 주소를 확인해보면, 매번 다른것을 확인 할수 있습니다. 이것은 매번 객체가 생성되었다는 것을 의미합니다.
개인들마다 결과를 보고 당연(?)하게 또는 이건 머지(?)하고 느끼는 분이 있을 듯합니다.
아마, 당연하게 느끼시는 분들은 x 와 y가 메모리의 다른 영역에 객체가 생성다고 느끼시는 분들이고, 의문을 가지시는 분들은 메모리 레퍼런스(reference) 참조를 왜 하지 않지? 라고 생각하시는 분들일 것입니다.
제가 여기서 중요하게 생각해봐야 할 부분은 객체의 ID, 주소가 계속 바뀌고, 즉, 메모리에 새로운 객체가 매번 생성된다는 의미 입니다. 이것은 저와 같은 c/c++ 개발자에게 객체 생성은 많은 비용(cost)이 든다고 배운 사람에게는 매우 금기시 되어 있는 부분입니다.
참조: Python은 GC(가비지 컬렉터)가 주기적으로 객체를 해제합니다.
2. mutable(가변) vs immuable(불가변) 객체
개인적으로 성능과 효율성 이슈로 Python 창조자는 객체를 아래의 기준으로 2가지로 분류하였다고 생각합니다.
# mutable(가변) 객체: 값 변경시 객체 ID(즉, 메모리 주소)가 변경되지 않는, 즉 생성된 처음 위치에서 변경가능
# immuable(불가변) 객체: 값 변경시에 새로운 객체를 생성, 즉 새로운 객체 ID(즉, 메모리 주소)를 가지게 하였습니다.
객체분류: https://choiwonwoo.tistory.com/entry/Python-Data-Types-Object-Types?category=969492
[Python] Data Types, Object Types
1.기본적 오브젝트 분류 2. 객체 종류 - 파이썬의 모든 변수는 객체의 인스턴스다. 그리고, 객체는 2종류로 구분(1. Mutable, 2. Immutable)된다. - 객체가 인스턴스화될 때마다 고유한 개체 ID가
choiwonwoo.tistory.com

예제를 보면, mutable 객체인 listX와 immutable 객체를 생성하고 값을 추가하는 같은 작업을 하지만, 메모리를 관리하는 부분이 확실하게 다름을 확인할수 있습니다.
3. 결론
간단하게 파이썬에서 메모리 관점을 가지고 변수를 생성 및 변경시 내부적으로 어떻게 동작하는 방법에 대해서 정리하였습니다. 이 부분은 심각하게 생각하지 않고 작업은 가능하지만, 실질적으로 프로젝트 결과물에 대한 성능평가시 큰 차이를 보이게 할 수 있습니다.