
[기본 이론]
# 기본 개념
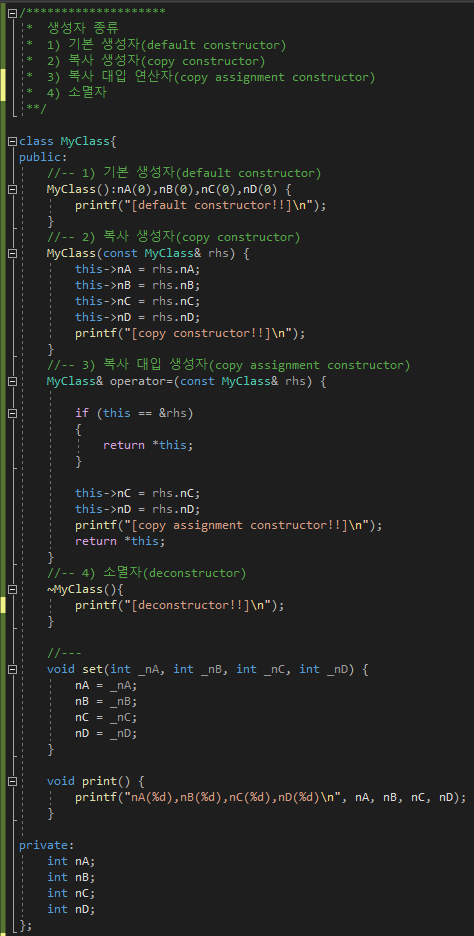
- 컴파일러는 클래스의 객체를 생성시 자동으로 생성자, 소멸자, 복사생성자, 복사 대입 연사자를 생성함
# (기본) 생성자란?
- 클래스(class)의 인스턴스(instance) or 객체(object)가 생성되는 시점에 자동으로 호출되는 특수한 멤버함수이다.
이 생성자 함수에서는 클래스의 멤버 변수 초기화를 담당함
# 소멸자란?
- 객체(object) 소멸시 자동으로 호출되는 함수
- 객체 메모리를 정리함
# 복사 생성자란?
- 기존에 있던 객체를 복사해서, 객체를 생성할 때 호출되는 생성자
- 자신과 같은 클래스 타입의 다른 객체에 대한 참조(reference)를 인수로 전달받아, 그 참조를 가지고 자신을 초기화
# 복사 대입 연산자라?
- 같은 타입의 객체를 이미 생성되어 있는 객체에 값을 복사할 때 호출되는 함수
# 깊은 복사(deep copy)와 얕은 복사 (shallow copy)
- 객체를 생성하고 초기화시킬 때 멤버 변수를 어떻게 초기화하느냐에 따라 깊은 복사가 될 수 있고, 얕은 복사가 될 수 있습니다.
----------------------------------------------------------------
[실무적인 정리]
지금까지는 C++을 배우면서 나오는 생성자에 관련된 이론을 정리하였습니다.
그런데, 저의 경우에 초심자일때는 어 머지(?)하는 부분이 있었습니다.
자 다시 간단히 정리하겠습니다.
복사 생성이란? 직관적으로 기존에 있던 것(객체)을 복사해서 생성하는 것이라고 정리하겠습니다.
왜? 계속 생성해서 사용하는 것보다, 이미 있는 것을 재사용하면 성능및 효율성이 좋다.
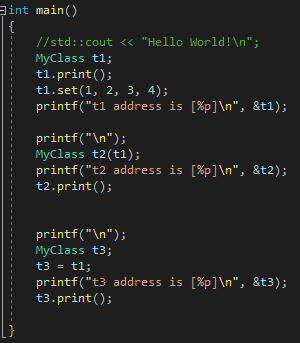
[예제1]
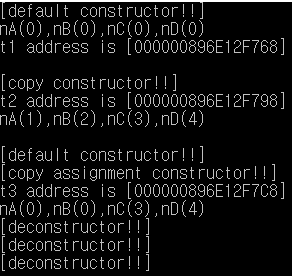
아래 코드를 보면, 복사생성자,대입연산자가 없는데??? 기능이 동작한다.
그 이유는? 컴파일러가 암묵적으로 아래의 코드에 복사생성자와 대입연산자를 생성하여 실행되기 때문입니다.
이것을 디폴트 복사생성자, 디폴트 대입연산자라고 합니다.
이렇게 컴파일러가 다해주면, 객체 복사관련하여 많은 시간을 왜 배워야 하는가??? 그것은 컴파일러가 모든것 또는 완벽
하게 개발자의 요구를 충족시켜 주지 못하기 때문입니다.(개인적인 생각)
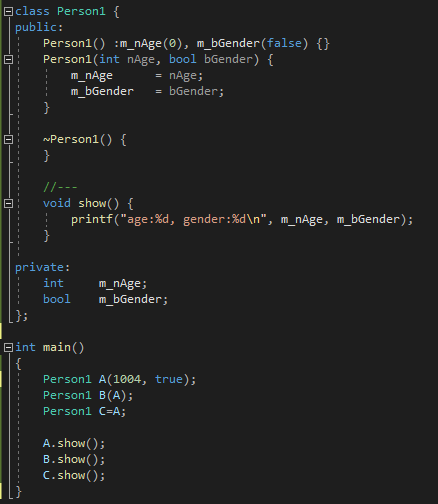
[예제2]
자 이제 공부를 해야 하는 이유를 알아 보겠습니다.
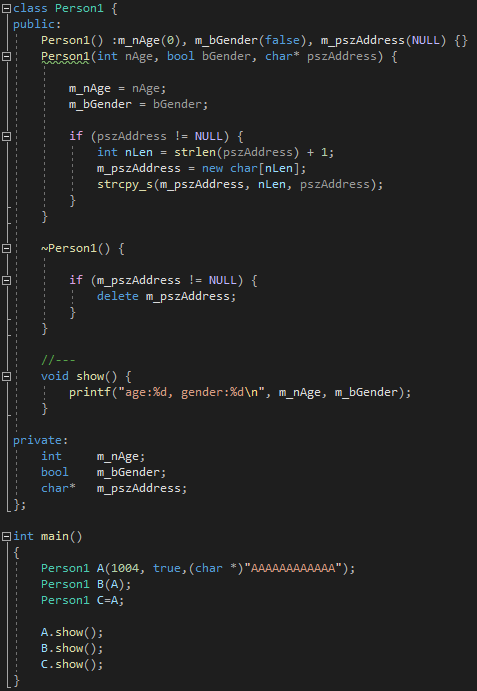
예제1과 예제2를 비교하여 보면, 차이점은 reference 멤버변수만 추가되었고, 나머지는 동일합니다.
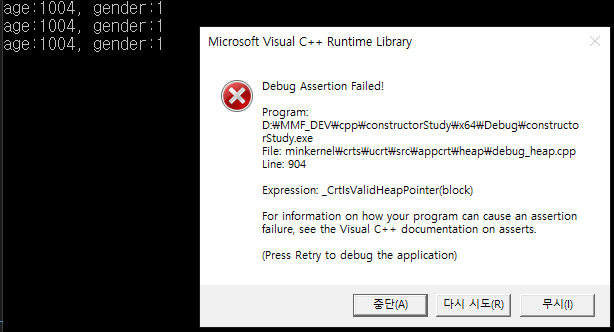
하지만 실행을 하여 보면, 정상적으로 동작하다가 위와 같은 crash error가 발생하는 것을 확인할수 있습니다.
그 이유는 객체 복사와 대입 연사자를 통해서, reference를 새로운 객체 B와 C에 정상적으로 전달되었지만, A, B, C 객체의 소멸자중 하나라도 호출되면, 남은 두개의 객체는 reference를 잃게되기 때문입니다.
기술적으로 이러한 문제점은 얕은 복사(shallow copy)의 문제점이라고 합니다.
여기서 얕은 복사(shallow copy)에 대한 정리를 하면, "객체 복사시 변수의 메모리 reference(주소)만 복사"하는 것을 의미합니다. ( call by value, call by reference 개념 필요) 여기서 중요점은 컴파일러가 자동지원(생성)하는 복사생성자와 대입연산자는 얕은 복사(shallow copy)만 지원한다. 그리고, 이 기능은 제한 점이 있다는 것이다.
이러한 문제점을 해결하기 위해서, 개발자는 생성자에 대해서 많은 시간을 투자하게 됩니다.
그리고, 이 얕은 복사(shallow copy)의 해결책은 깊은 복사(deep copy)입니다.
[예제3]
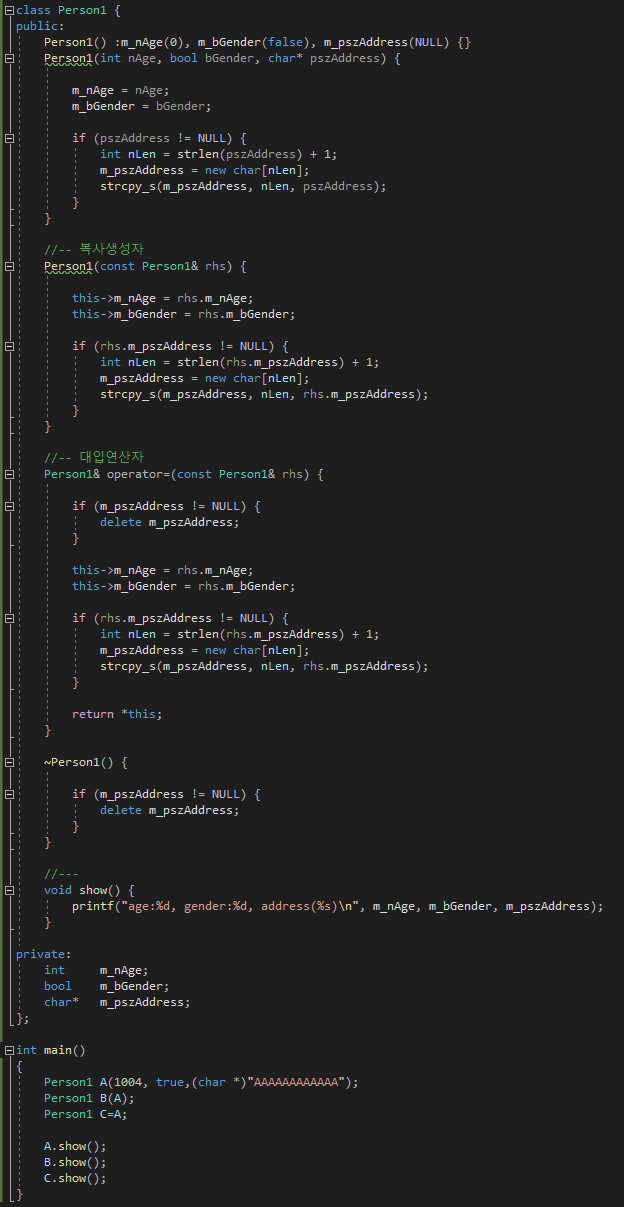

예제3 코드를 보면, 복사 생성자와 대입 연산자가 추가된것을 볼수있습니다. 그리고, 실행결과는 예제2와 다르게 에러가 발생하지 않습니다. 그리고, 그 해결책은 객체복사 reference 변수의 메모리를 새로 할당해주는 것을 깊은 복사(deep copy)라고 합니다. (참고로, 이렇게 하면 메모리와 성능은 떨어집니다.)
[개인적 생각]
솔직히 신입일때 좀 허무했던것 같습니다. 결국에는 개인적으로 c++ 오버로딩과 메모리 관리로 해결이 된 것으로 생각되었습니다. 하지만, 많은 이론을 공부했습니다. (여러종류의 생성자, 깊은복사/얕은 복사등... )
z파이썬은 모든 것이 Object이다. 그리고, Object를 비교는 2가지 관점으로 고려된다.
1) 같은 Object인가?(같은 인스턴스인가?) --> 비교연산자: is
2) Object value 값이 같은가? --> 비교연산자 ==
예제)


# 예제1 과 결과1를 보면, "is" 비교 연산자는 object의 id, 즉, memory address가 같으면 True를 반환함을 확인
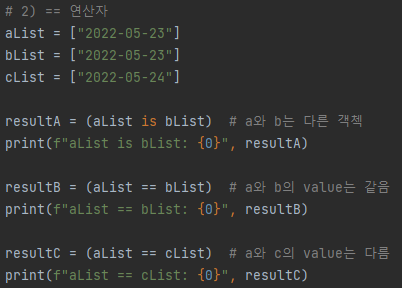
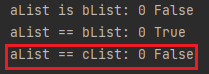
# 예제2 과 결과2를 보면, "==" 비교 연산자는 object가 가지고 있는 실제 value를 비교하여 같으면 True를 반환
# 여기서 전제조건은 같은 Data typs이여야 함
저의 경우에는 C/C++, Java 개발 언어를 선경험하고, Python을 접하게 되었을때 객체 종류(mutable,immutable)에 대한 부분은 많이 낯설게 느껴지는 부분이었습니다. 그래서, 초기에 이 부분에 많은 시간을 할애하여 공부하였습니다.
저는 아래의 두줄에 대한 내용을 간단히 정리하고자 합니다.
"파이썬의 모든것은 객체(object) 이고, 객체는 두가지(mutable vs immutable)로 분류된다.
또한, 객체는 나타내는 변수는 값(value)에 대한 참조(reference)이다."
참고로, 객체는 class라고 기능과 다양한 데이터의 조합이고, 이 클래스의 인스턴스(instance)를 객체(object)라고 합니다.
인스턴스란 class가 메모리의 영역에 할당되었다는 것을 의미함
1. 기본적인 접근
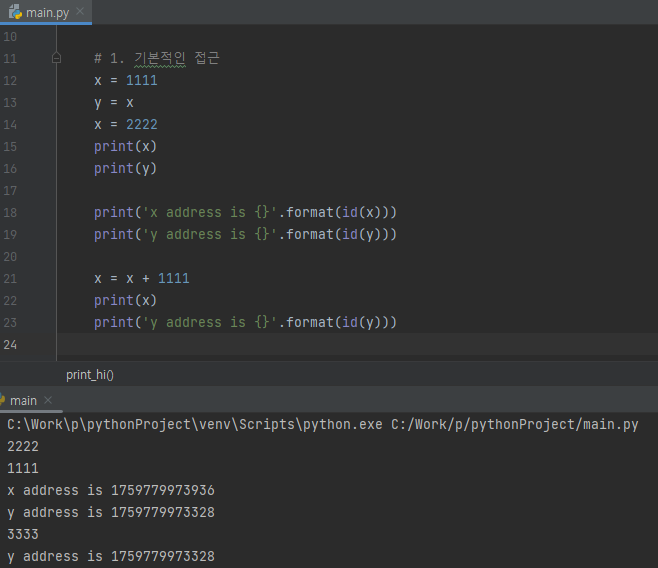
위의 예제와 실행결과를 간단히 보면, 변수 y에 변수 x값을 넣고, 변수 x의 값을 변경하였습니다. 이때, 마다 객체의 주소를 확인해보면, 매번 다른것을 확인 할수 있습니다. 이것은 매번 객체가 생성되었다는 것을 의미합니다.
개인들마다 결과를 보고 당연(?)하게 또는 이건 머지(?)하고 느끼는 분이 있을 듯합니다.
아마, 당연하게 느끼시는 분들은 x 와 y가 메모리의 다른 영역에 객체가 생성다고 느끼시는 분들이고, 의문을 가지시는 분들은 메모리 레퍼런스(reference) 참조를 왜 하지 않지? 라고 생각하시는 분들일 것입니다.
제가 여기서 중요하게 생각해봐야 할 부분은 객체의 ID, 주소가 계속 바뀌고, 즉, 메모리에 새로운 객체가 매번 생성된다는 의미 입니다. 이것은 저와 같은 c/c++ 개발자에게 객체 생성은 많은 비용(cost)이 든다고 배운 사람에게는 매우 금기시 되어 있는 부분입니다.
참조: Python은 GC(가비지 컬렉터)가 주기적으로 객체를 해제합니다.
2. mutable(가변) vs immuable(불가변) 객체
개인적으로 성능과 효율성 이슈로 Python 창조자는 객체를 아래의 기준으로 2가지로 분류하였다고 생각합니다.
# mutable(가변) 객체: 값 변경시 객체 ID(즉, 메모리 주소)가 변경되지 않는, 즉 생성된 처음 위치에서 변경가능
# immuable(불가변) 객체: 값 변경시에 새로운 객체를 생성, 즉 새로운 객체 ID(즉, 메모리 주소)를 가지게 하였습니다.
객체분류: https://choiwonwoo.tistory.com/entry/Python-Data-Types-Object-Types?category=969492
[Python] Data Types, Object Types
1.기본적 오브젝트 분류 2. 객체 종류 - 파이썬의 모든 변수는 객체의 인스턴스다. 그리고, 객체는 2종류로 구분(1. Mutable, 2. Immutable)된다. - 객체가 인스턴스화될 때마다 고유한 개체 ID가
choiwonwoo.tistory.com

예제를 보면, mutable 객체인 listX와 immutable 객체를 생성하고 값을 추가하는 같은 작업을 하지만, 메모리를 관리하는 부분이 확실하게 다름을 확인할수 있습니다.
3. 결론
간단하게 파이썬에서 메모리 관점을 가지고 변수를 생성 및 변경시 내부적으로 어떻게 동작하는 방법에 대해서 정리하였습니다. 이 부분은 심각하게 생각하지 않고 작업은 가능하지만, 실질적으로 프로젝트 결과물에 대한 성능평가시 큰 차이를 보이게 할 수 있습니다.