
'MINERVA/Python'에 해당되는 글 48건
- 2025.10.02 :: [Python] 정규식 과 f-string 사용(우연히(?)동작)
- 2024.10.19 :: [Python] multi-threading & async 설명 3
- 2024.09.06 :: [Python] FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated 1
- 2024.08.01 :: [Python] 변수 초기화: 타입 힌팅(Type Hinting)
- 2024.06.06 :: [Python] DataFrame의 특정 열이 object 타입으로 저장된 시간 문자열
- 2024.06.06 :: [Python] 문자열 비교 연산자: is(is not) vs ==(!=) 1
- 2024.05.12 :: [Python] Message: session not created: This version of ChromeDriver only supports Chrome version 119
- 2024.03.09 :: [Python] 윈도우 anaconda 32bit 환경에서 python 3.12 설치(?)
- 2024.03.02 :: [Python] UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
- 2024.01.30 :: [Dataframe] 키 값이 같은 row가 2개 이상, 하나 row만 남기는 방법
오늘 그동안 우연히(?) 그것도 오랫동안 잘 동작하는 코드에 문제가 생겨서, 하루 종일 고생을 해서 내용을 정리함.
1. 기존방식: (\d{6})
pattern_a = re.compile(rf"{file_key}_(\d{6})_(\d{6})\.xlsx")- 정상적으로 동작하다가 에러가 발생
- 에러: {6} 는 f-string 문법에서 "변수를 포맷팅할 때 쓰는 중괄호"로 인식 -> 그동안 어떻게 동작했지?
- 에러 원인: 추측하기로는 파이썬이 이걸 f-string의 포맷팅 구문으로 보려고 하다가, 6은 변수도 아니고 포맷 명세도 아닌데 그냥 "6"으로 인식해서 에러가 발생함(구글링을 해보니, 보통은 잘된다고 나옴 ㅠㅠㅠ)
- 해결 아래와 같이 안전한 방식으로 하는게 최고임
2. 개선방식: (\d{{6}})
pattern_b = re.compile(rf"{file_key}_(\d{{6}})_(\d{{6}})\.xlsx")- {{ 와 }} 는 f-string에서 중괄호 이스케이프이기때문, f-string이 해석할 때 {{6}} → 문자열 "{6}" 으로 변환됨
- 안전한 방식으로 하자
3. 결론
- 정규식에 {n} 패턴을 쓸 때는 f-string 안에서는 반드시 {{n}} 로 써야함.
'십시일반'이라는 말이 있듯이, 프로그램 성능을 향상시키기 위해서는 모든 개발 언어에서, multi-threading과 async는 매우 중요합니다. 저 역시, 개발자로서 초기에 매우 많은 시간을 투자하였습니다.
근래에는, 파이썬으로 많은 작업을 하면서 개발을 하는데 무리는 없지만, 간단하게 해당 내용을 정리 및 기록하고자 합니다.
[코드]
- 모든 작업은 동일한 print_numbers()와 print_letters() 함수를 각각 쓰레딩 및 async 방법으로 실행시 성능 테스트
- 0) single_thread 실행을 기준으로 추가적인 1)threading ~5)gevent방법을 비교해보자.
import os
import threading
import concurrent.futures
import multiprocessing
import asyncio
import gevent
import time
##################
# 공통 함수
###
def print_numbers():
for i in range(1, 6):
time.sleep(1)
def print_letters():
for letter in ['A', 'B', 'C', 'D', 'E']:
time.sleep(1)
##################
# 0) single_thread 에서 순차적으로 실행
###
def single_thread_module():
start_time = time.time()
print_numbers()
print_letters()
end_time = time.time()
print(f"Single-thread execution time: {end_time - start_time:.2f} seconds")
##################
# 1) 표준 라이브러리의 threading 모듈을 사용
# - 글로벌 인터프리터 락(GIL)로 인해 CPU 바운드 작업에는 한계가 있음.
###
def threading_module():
start_time = time.time()
# Thread 객체 생성
t1 = threading.Thread(target=print_numbers)
t2 = threading.Thread(target=print_letters)
# Thread 시작
t1.start()
t2.start()
# Thread 료될 때까지 대기
t1.join()
t2.join()
end_time = time.time()
print(f"Threading execution time: {end_time - start_time:.2f} seconds")
##################
# 2) concurrent.futures.ThreadPoolExecutor 사용
# [비교]
# 쓰레드를 직접 관리하는 대신, 작업을 스레드 풀에 제출하고, 비동기적으로 처리
# 자동으로 쓰레드 종료를 관리
###
def concurrent_mudule():
start_time = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
future1 = executor.submit(print_numbers)
future2 = executor.submit(print_letters)
concurrent.futures.wait([future1, future2])
end_time = time.time()
print(f"ThreadPoolExecutor execution time: {end_time - start_time:.2f} seconds")
##################
# 3) multiprocessing 사용
# - 파이썬 GIL(Global Interpreter Lock) 특성 때문에 CPU 바운드 작업경우 멀티 쓰레딩 성능 하락이 발생에 대한 해결책!
# 그 이유? 멀티 프로세싱을 하기때문에 간섭(?이 발생하지 않음
###
def multiprocessing_module():
start_time = time.time()
p1 = multiprocessing.Process(target=print_numbers)
p2 = multiprocessing.Process(target=print_letters)
p1.start()
p2.start()
p1.join()
p2.join()
end_time = time.time()
print(f"Multiprocessing execution time: {end_time - start_time:.2f} seconds")
##################
# 4) asyncio 모듈을 사용한 비동기 프로그래맹(멀티 쓰레딩 하님)
# - asyncio는 코루틴을 사용해 비동기적으로 I/O 바운드 작업을 수행(CPU 바운드 작업 비추)
# - 단일 스레드에서 실행되지만, 비동기 방식으로 여러 작업을 동시에 처리(동시성 지원)
###
async def async_print_numbers():
for i in range(1, 6):
await asyncio.sleep(1)
async def async_print_letters():
for letter in ['A', 'B', 'C', 'D', 'E']:
await asyncio.sleep(1)
async def main():
task1 = asyncio.create_task(async_print_numbers())
task2 = asyncio.create_task(async_print_letters())
await task1
await task2
def asyncio_module():
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"Asyncio execution time: {end_time - start_time:.2f} seconds")
##################
# 5) gevent
# - gevent는 코루틴을 기반으로 한 라이브러리로, 네트워크 작업 등에서 동시성을 극대화할
# - 비동기 방식이지만, 코드가 매우 간결해지는 장점
###
def gevent_module():
start_time = time.time()
g1 = gevent.spawn(print_numbers)
g2 = gevent.spawn(print_letters)
gevent.joinall([g1, g2])
end_time = time.time()
print(f"Gevent execution time: {end_time - start_time:.2f} seconds")
if __name__ == '__main__':
print(f'{__file__}')
print(f'{os.path.dirname(__file__)}')
single_thread_module()
threading_module()
concurrent_mudule()
multiprocessing_module()
asyncio_module()
gevent_module()
[실행 결과]
D:\mmPRJ\64B\mmFNAVI\mmThread_Work.py
Single-thread execution time: 10.07 seconds
Threading execution time: 5.03 seconds
ThreadPoolExecutor execution time: 5.04 seconds
Multiprocessing execution time: 5.31 seconds
Asyncio execution time: 5.02 seconds
Gevent execution time: 10.06 seconds
[정리]
- 파이썬에서 멀티쓰레딩을 구현하는 방법은 여러 가지가 있으며, 사용하려는 작업의 성격(예: CPU 바운드, I/O 바운드)에 따라 적합한 방법을 선택해야 합니다.
- GIL을 피하고 CPU 바운드 작업인 경우는 multiprocessing 사용
- asyncio는 단일 스레드에서 비동기 처리를 지원하는 I/O 바운드 작업에 적합
- 테스트 방법이 CPU 바운드 작업이 아닌 단순 지연기 때문에, 멀티쓰레딩/비동기 방식이 비슷한 성능을 보일 것으로 예상되지만, 상황에 따라 다를 수 있습니다.
[경고 전문]
FutureWarning: The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[의미]
FutureWarning 메시지는 pandas의 DataFrame을 결합할 때, 빈 값(NA 또는 None)이나 전부 NA인 열이 있을 경우 향후 버전에서는 이를 처리하는 방식이 변경될 것이라는 경고입니다. 현재 pandas는 이런 열들을 무시하고 처리하지만, 미래에는 이를 고려해 결과의 데이터 유형(dtype)을 결정할 것입니다.
이 경고를 해결하려면, concat 작업 전에 빈 열이나 모두 NA인 열을 미리 제거하거나 제외해야 합니다. 이를 위해 dropna() 또는 열 필터링을 사용할 수 있습니다.
import pandas as pd
# 여러 개의 DataFrame 예시 (빈 값 또는 전부 NA인 열 포함)
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [None, None, None]})
df2 = pd.DataFrame({'A': [4, 5, 6], 'B': [None, None, None]})
# DataFrame들을 결합하기 전에 모든-NA 열 제거
df1_cleaned = df1.dropna(axis=1, how='all')
df2_cleaned = df2.dropna(axis=1, how='all')
# 결합
combined_df = pd.concat([df1_cleaned, df2_cleaned], ignore_index=True)
# 결과 출력
print(combined_df)
1) dropna(axis=1, how='all'): 모든 값이 NA인 열을 제거합니다.
axis=1은 열을 기준으로 작업하는 것이고, how='all'은 모든 값이 NA인 열만 제거하라는 의미입니다.
( 부분은 how='any')
2) pd.concat([df1_cleaned, df2_cleaned]): 이후 concat을 사용해 DataFrame을 결합합니다.
파이썬은 data type assgnment 언어입니다. 그런데, 코드를 보다 보면 C/C++과 유사하게 변수를 초기화할때 데이타 타입을 명시해주는 경우가 있습니다. 이렇게 코딩을 하는 것을 타입 힌팅(Type Hinting)라고 하는데, 프로그램 성능에는 영향이 없으나, IDE의 코드 분석 기능에 도움을 주게 됩니다.
아래에 간단하게, 파이썬에서 변수를 초기화하는 2가지 방법의 차이점을 을 정리합니다.
1. max_value: int = 100
- 타입 힌팅(Type Hinting): 여기서 : int는max_value변수가 정수형(int)임을 명시하는 타입 힌트(type hint)입니다.
- 주로 사용 목적: 이는 변수의 타입을 명시적으로 표시하여 코드의 가독성을 높이고, 정적 타입 검사 도구(static type checker)나 IDE의 코드 분석 기능을 돕기 위해 사용됩니다.
- 실행 시간 영향: 타입 힌팅은 실행 시간에는 아무런 영향을 미치지 않으며, 이는 런타임에 무시됩니다. 이는 오직 개발 도구가 이를 사용하여 타입을 추론하고 경고를 발생시키기 위한 것입니다.
2. max_value = 100
- 기본적인 변수 초기화: 이는 기본적인 변수 초기화 방법입니다. 변수가 정수형인지 명시적으로 표시하지 않습니다.
- 주로 사용 목적: 일반적인 변수 초기화 방식이며, 타입을 명시적으로 표시하지 않아도 될 때 사용합니다.
- 실행 시간 영향: 타입 힌팅이 없는 것과 마찬가지로, 이는 런타임에 실행되어 변수max_value에 값을 할당합니다.
요약
- 타입 힌팅(: int): 코드를 더 명확하고 가독성 높게 만들며, 정적 분석 도구의 도움을 받을 수 있습니다.
- 변수 초기화(= 100): 기본적인 변수 초기화 방식이며, 타입 힌트 없이 변수를 초기화합니다.
예를 들어, 아래와 같이 타입 힌팅을 사용하면 IDE에서 자동 완성 기능을 제공하거나 타입 오류를 사전에 검출할 수 있습니다:
보통 시간 데이타의 경우 datetime 타입을 사용하게 되는데, 특이(?)하게 데이타 값은 시간형식인데 데이타 타입이 문자열인 경우가 있습니다. 이런 경우 해당 컬럼을 기반으로 시간 필터링을 해야하는 경우 타입 변환을 필요로 하게 됩니다.
이런 케이스를 위해 예제 코드입니다.
import pandas as pd
data = {
'time': ['09:05:43', '12:30:00', '15:45:20', '08:15:10', '10:30:00']
}
df = pd.DataFrame(data)
# 시간 문자열을 datetime으로 변환 (시간 형식 명시)
df['time'] = pd.to_datetime(df['time'], format='%H:%M:%S').dt.time
# 필터링할 시간 범위 설정
start_time = pd.to_datetime('09:00:00', format='%H:%M:%S').time()
end_time = pd.to_datetime('12:00:00', format='%H:%M:%S').time()
# 시간 범위로 필터링
filtered_df = df[(df['time'] >= start_time) & (df['time'] <= end_time)]
print(filtered_df)
코드 구성은 다음과 같습니다.
1. 시간 문자열을 datetime 타입 객체로 변환하고,
' dt.time'을 사용해서, datetime 객체에서 시간(time)만 추출
2. 필러링을 위한 시간 설정
주어진 시간 형식의 문자열을 시간 객체로 변환하고,특정 시간 범위 내의 데이터만 필터링하는 방법을 보여줍니다.
Python에서 문자열 객체를 비교할 때 is(is not) 연산자를 사용하는 것은 권장되지 않습니다.
대신 ==(!=) 연산자를 사용하는 것이 적절합니다 .
그 이유는 다음과 같습니다.
1. 'is(is not) 연산자': 객체의 reference를 비교합니다. 즉, 두 객체가 같은 메모리위치를 참조하는지를 확인합니다.
2. '==(!=) 연산자': 객체의 값을 비교합니다. 두 객체의 값이 동일한지를 확인합니다.
[예제]
a = "hello"
b = "hello"
c = "world"
print(a is not b) # 이것은 False를 출력합니다. (같은 메모리 위치를 참조하기 때문)
print(a != c) # 이것은 True를 출력합니다. (값이 다르기 때문)[Python] Message: session not created: This version of ChromeDriver only supports Chrome version 119
프로그램이에서 아래 에러 메시지를 연락을 받고, 해결방법에 대한 내용을 정리하였습니다.

에러 메시지 내용을 보면, ChromeDriver와 Chrome 브라우저 사이에 버젼 미스매치라는 확인 가능합니다.
그러므로, 이 버전을 차이를 맞추면 에러는 해결됩니다.
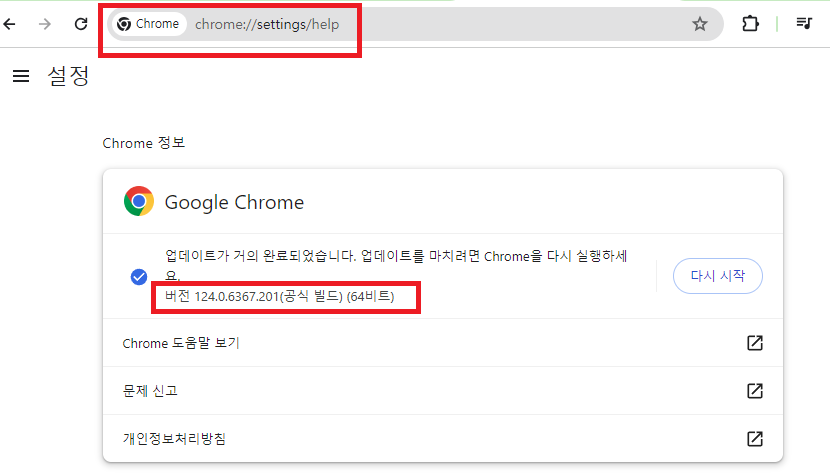
1. Chrome 브라우저 버전 확인
>> 주소창: chrome://settings/help
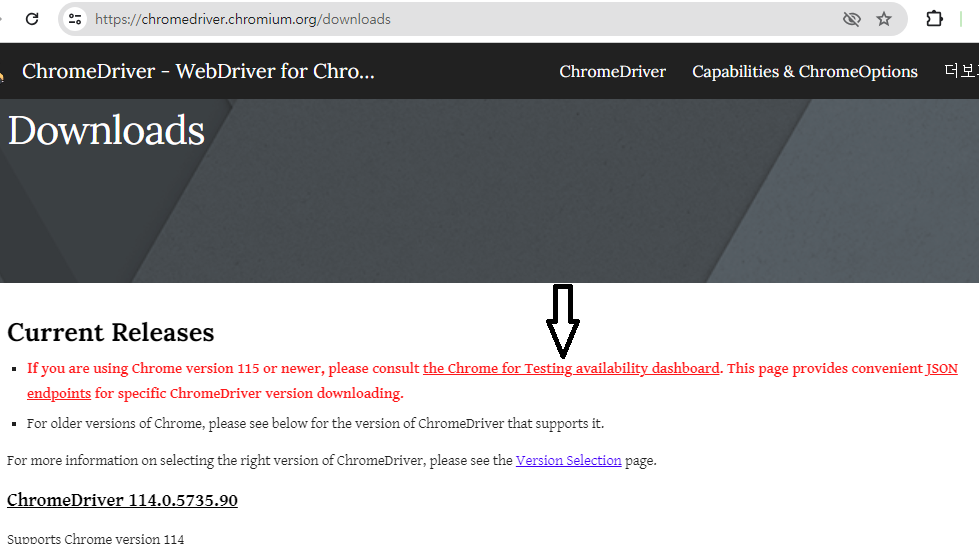
2. WebDriver: ChromeDrive 다운로드
>> https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 115 or newer, please consult the Chrome for Testing availability dashboard. This page provides convenient JSON endpoints for specific ChromeDriver version downloading. For older versions of Chrome, please se
chromedriver.chromium.org
Chrome 브라우저 버전에 맞는 WebDriver 다운로드를 함.
제 경우는 stable 124.0.6367.201 선택
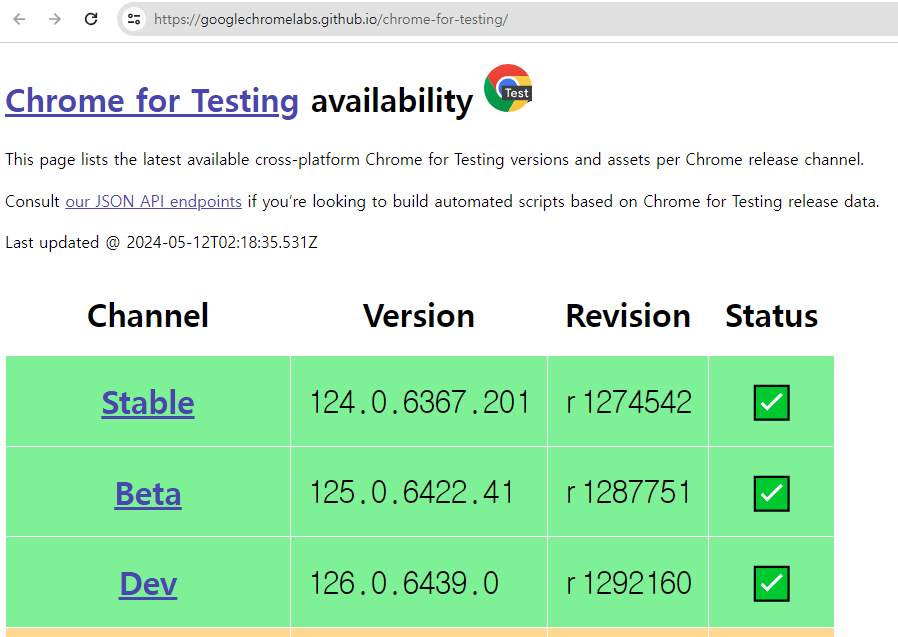
3. 기본 코드
webDriverPath = 'D:/Dev/chromedriver/chromedriver.exe'
# 브라우저 꺼짐 방지
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
# 브라우저 생성
browser = webdriver.Chrome(webDriverPath,options=chrome_options)
# 사이트 열기
browser.get('https://www.naver.com/')
browser.implicitly_wait(10) # 로딩 10초
#
#browser.close() # 브라우저 현재 tab(화면)만 종료
#browser.quit() # 브라우저 모든 tab(화면) 종료
print(f'[trassWebCrawler] Day:{strPivotDay} Period:{nPeriod} is done')
DM을 통해서 '윈도우 anaconda 32bit 환경에서 python 3.12 설치'관련해서 문의 주신 분이 있어 정리를 합니다.
우선, 결론적으로 말씀드리면, 현재(2024년 3월 09일)는 32bit에 설치가능한 Python 3.12는 아직 출시되지 않았습니다.
해당 내용을 확인하는 방법을 자세히 설명드리겠습니다.
1. Python 배포 버젼확인
https://www.python.org/downloads/windows/
Python Releases for Windows
The official home of the Python Programming Language
www.python.org
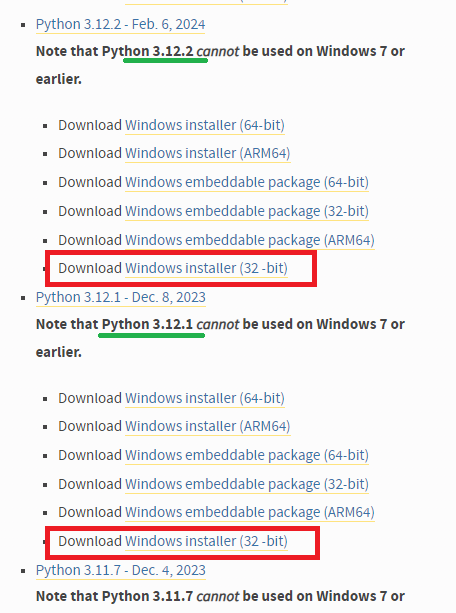
파이썬 다운로드 사이트에 보면, 버전 3.12에 대한 32bit 버전이 정상적으로 배포되고 있습니다.
2.Anaconda 배포 버전확인
Python :: Anaconda.org
Description Python is a widely used high-level, general-purpose, interpreted, dynamic programming language. Its design philosophy emphasizes code readability, and its syntax allows programmers to express concepts in fewer lines of code than would be possib
anaconda.org
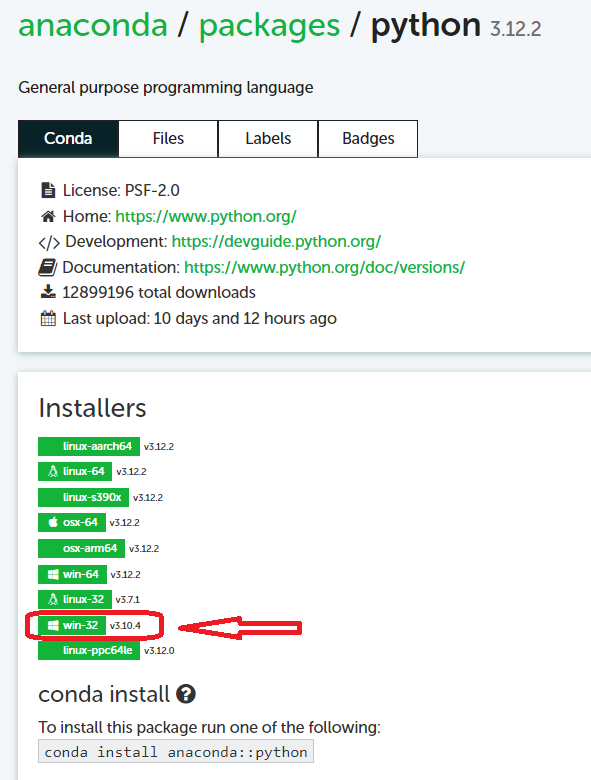
아나콘다 다운로드 사이트를 보면, 윈도우 32bit 버전에 대해서는 Python 3.10.4까지 지원됨을 확인 할수 있습니다.
감사합니다.
해당 에러메시지 내용을 보면, 파서가 날짜 형식을 자동으로 결정(추론)할 수 없고, 그래서 일관성과 정확성을 위해 명시적으로 형식을 지정하라고 요구합니다..(유사한 예로, C++의 STATIC_CASTING을 생각하시면 됩니다.)
아래의 코드를 보면, 직관적으로 이해가 가능하실것입니다.
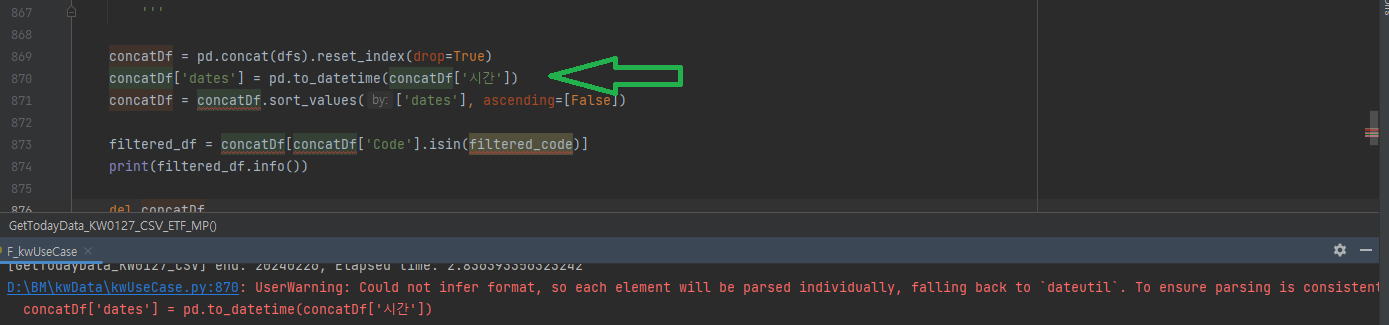
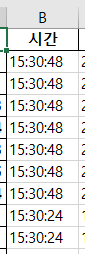
변환을 하고자 하는 시간데이타는 위와 같습니다.
위와 같이 시간데이타의 foramt이 '시간:분:초'로 되어 있으므로, 아래와 같이 수정하면 됩니다.
#concatDf['dates'] = pd.to_datetime(concatDf['시간'])
(수정) concatDf['dates'] = pd.to_datetime(concatDf['시간'], format='%H:%M:%S')
추가적으로 데이타의 format이 '연-월-일'인 경우는 아래와 같이 수정하면 됩니다.
concatDf['dates'] = pd.to_datetime(concatDf['dates'], format='%Y-%m-%d')
Pandas를 사용하여 DataFrame에서 특정 키 값이 같은 행이 두 개 이상일 때, 날짜 또는 최근 업데이트된 행만 남기는 방법은 다음과 같이 할 수 있습니다
아래와 같이 기본데이타를 보면,
data = {'key': ['A', 'B', 'A', 'B', 'C'],
'날짜': ['2024-01-01', '2024-02-01', '2024-03-01', '2024-02-15', '2024-04-01'],
'값': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
print(df)
key 날짜 값
0 A 2024-01-01 10
1 B 2024-02-01 20
2 A 2024-03-01 30
3 B 2024-02-15 40
4 C 2024-04-01 50
Key가 같은 데이타가 불규칙하게 중복되어 있습니다.
해당 데이타에서 키값을 기준으로 마지막 데이타만 추출하는 방법은 아래와 같습니다.
result_df = df.sort_values(by='날짜').drop_duplicates('key', keep='last')
print(result_df) key 날짜 값
3 B 2024-02-15 40
2 A 2024-03-01 30
4 C 2024-04-01 50
이 코드에서 sort_values 함수는 '키'를 사용하여 오름 차순(default)으로 정열합니다.
그리고, drop_duplicates 함수를 사용하여 키 열을 기준으로 중복된 행을 제거하는데, 마지막행(keep='last'을 남기게 됩니다.
추가적으로, 중복행을 제거할때, 정렬된 행의 처음 행을 남길때는 keep='first' 로 설정하면 됩니다.