
'MINERVA/Python'에 해당되는 글 48건
- 2023.08.20 :: [Python] WARNING: Ignoring invalid distribution 1
- 2023.08.20 :: [Python] ModuleNotFoundError: No module named 'pip'
- 2023.04.28 :: [Python] 특정 날짜 기준으로 working day 날짜확인(공휴일,대체공휴일반영)
- 2023.04.28 :: [Dataframe] column 데이타 타입 전환 방법 정리
- 2023.04.04 :: [Python] DataFrame Row를 List로 전환
- 2023.04.03 :: [Python] 특정 컬럼을 기준으로 dataframe을 비교하여, 다른 ROW를 추출
- 2023.04.03 :: [Panda] 두 개의 DataFrame에서 특정 열(column)을 기준으로 다른 값을 가지는 행(row)을 추출하는 방법
- 2023.02.11 :: [Python] 공백(Blank)이란? Empty or Space
- 2022.11.16 :: [Python] 두개 리스트(list)를 딕셔너리(dictionary)로 만들기
- 2022.11.12 :: [Python] dataframe 결합 또는 합치기 - UNION 1
pip 업데이트를 진행시, 위와 같은 경고(warning)을 보게되는 경우가 있습니다.
개발을 진행하는 데는 문제가 없지만, 기분이 깔끔하지 않기에 아래와 같은 경고 메시지가 보였을때는 아래와 같이 처리하 처리하면 됩니다.

발생원인은 업데이트를 진행하는 디렉토리에 먼가 이상한, 유효한지 않은(invalid) 내용이 있기 때문입니다.
그래서 경고가 발생한 패키지의 디렉토리를 확인해보면, 이상한 디렉토리가 존재하는 것을 확인 할수 있습니다.
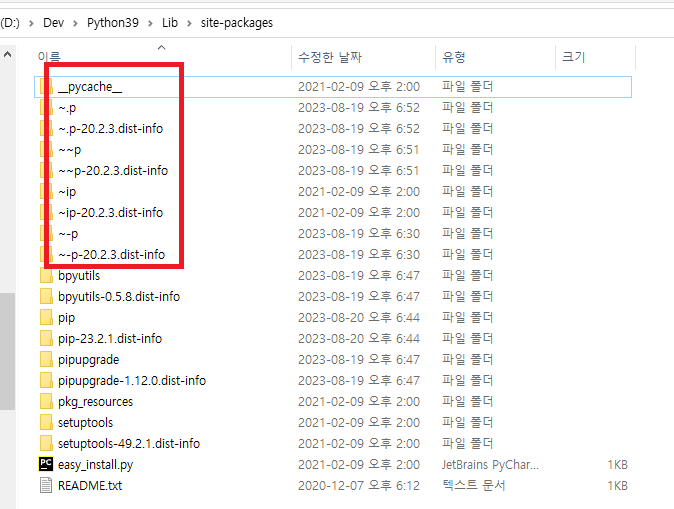
임시디렉토리(~)가 생긴 원인은 이전에 업데이트를 진행하면서 실패하였을때 생긴것으로 추정됩니다.
일단 위의 임시디렉토리(~)를 모두 지워주세요.
그리고, 다시 업데이트 진행하여주시면 경고문 없이 진행되는 것을 확인하실수 있습니다.
감사합니다.
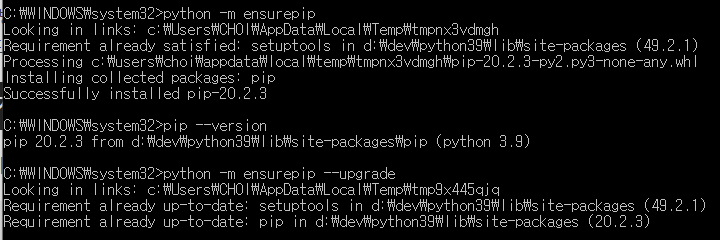
주기적으로 프로젝트 파이썬 패키지를 일괄 업데이트를 하는데, 갑자기(?) 아래와 같이 pip가 또(?) 말썽을 부리네요.

왜 이게 발생하는지 정확히는 모르겠지만, 발생하는 몇가지 패턴(?)은 있는것 같다.
그래도 일단은 일이 급하니 위와 같은 에러 발생시 해결하는 방법을 간단히 정리하자 합니다.
해결방법은 아래와 같습니다.
>> python -m ensurepip
공휴일과 대체 공휴일 확인을 위해서, nework API를 통해서 확인하는 부분을 정적으로 전환(이유: 방화벽과 속도 문제등)
import time
import datetime
from pytimekr import pytimekr
# alternative holiday: 대체휴일
alterHolidayList = ['20230124','20230501','20230529']
# 주말(weekend) & 연휴(holiday) & 대체휴일(alterHolidayList)
def CheckOffDay(d):
holidayList = pytimekr.holidays()
bHoliday = holidayList.__contains__(d)
bWeekday = d.weekday() > 4
strCheckDay = d.strftime('%Y%m%d')
bAlterday = alterHolidayList.__contains__(strCheckDay)
return(bWeekday or bHoliday or bAlterday)
# working day를 구해서 list로 반환
def GetWorkingDay(strBaseDay,nWorkingDay = 1): # 1은 당일 하루를 의미
nWorkingDayList = []
# string -> datatime
dtBaseDay = datetime.datetime.strptime(strBaseDay, '%Y%m%d')
print(dtBaseDay)
print(dtBaseDay.date())
for day in range(0,nWorkingDay):
while CheckOffDay(dtBaseDay.date()):
dtBaseDay = dtBaseDay - datetime.timedelta(days=1)
nWorkingDayList.append(dtBaseDay.strftime('%Y%m%d'))
dtBaseDay = dtBaseDay - datetime.timedelta(days=1)
return nWorkingDayListif __name__ == '__main__':
strBaseDay = '20230505' # 보통 오늘 기준으로 시총, 상장주식수등 고려
nWorkingDay = 6 # 오늘 포험, 실제 일하는 날만
dayList = GetWorkingDay(strBaseDay,nWorkingDay)
print(dayList)라이브 코드에서, 해당 기능 단위 테스트 코드부분을 발취
[실행결과]
['20230504', '20230503', '20230502', '20230428', '20230427', '20230426']
Pandas에서 데이터프레임의 열(column)의 데이터 타입을 변경하는 방법은 아래와 같습니다.
- astype() 메서드 사용
- astype() 메서드는 데이터프레임 내의 모든 값을 지정한 데이터 타입으로 변환합니다.
- 예시: df['column_name'] = df['column_name'].astype('int')
- to_numeric() 메서드 사용
- to_numeric() 메서드는 데이터프레임 열의 값을 수치형으로 변환합니다.
- 예시: df['column_name'] = pd.to_numeric(df['column_name'], errors='coerce')
- to_datetime() 메서드 사용
- to_datetime() 메서드는 데이터프레임 열의 값을 날짜/시간형으로 변환합니다.
- 예시: df['column_name'] = pd.to_datetime(df['column_name'], format='%Y-%m-%d')
- apply() 함수 사용
- apply() 함수는 데이터프레임 열의 각 값을 특정 함수에 적용하여 변환합니다.
- 예시: df['column_name'] = df['column_name'].apply(lambda x: x.lower())
개인적으로 적합한 방법을 선택하여 데이터프레임 열의 데이터 타입을 변경할 수 있습니다.
각 케이스별 구체적인 예는 아래와 같습니다.
1. astype()
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': ['23', '35', '27', '29', '31'],
'score': [80, 90, 75, 85, 95]}
df = pd.DataFrame(data)문자열로 된 'age'열이 포함된 데이터프레임이 있다고 가정해봅시다. 여기서 'age'열의 데이터 타입을 정수형으로 변경하려면 다음과 같이 astype() 메서드를 사용할 수 있습니다.
df['age'] = df['age'].astype(int)위 코드에서 df['age']는 'age'열에 해당하는 시리즈(Series) 객체를 반환하고, astype(int)는 해당 시리즈의 모든 값들을 정수형으로 변환한 후 다시 시리즈 객체를 반환합니다. 마지막으로 이 값을 다시 'age'열에 대입하여 'age'열의 데이터 타입을 정수형으로 변경합니다.
2. to_numeric()
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': [23, 35, 27, 29, 31],
'score': ['80', '90', '75', '85', '95']}
df = pd.DataFrame(data)문자열로 된 'score'열이 포함된 데이터프레임이 있다고 가정해봅시다.여기서 'score'열의 데이터 타입을 정수형으로 변경하려면 다음과 같이 to_numeric() 메서드를 사용할 수 있습니다.
df['score'] = pd.to_numeric(df['score'])위 코드에서 pd.to_numeric(df['score'])는 'score'열의 모든 값을 수치형으로 변환한 후 시리즈 객체를 반환합니다. 이 값을 다시 'score'열에 대입하여 'score'열의 데이터 타입을 수치형으로 변경합니다. 만약 'score'열에 수치형이 아닌 값이 있으면 해당 값은 NaN(Not a Number)으로 변경됩니다. 이때 to_numeric() 메서드의 errors 매개변수를 'coerce'로 지정하면 수치형으로 변환할 수 없는 값을 NaN으로 변환할 수 있습니다. 예를 들어 다음과 같이 사용할 수 있습니다.
df['score'] = pd.to_numeric(df['score'], errors='coerce')3. to_datetime()
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': [23, 35, 27, 29, 31],
'date': ['2022-04-20', '2022-04-21', '2022-04-22', '2022-04-23', '2022-04-24']}
df = pd.DataFrame(data)문자열로 된 'date'열이 포함된 데이터프레임이 있다고 가정해봅시다.여기서 'date'열의 데이터 타입을 날짜/시간형으로 변경하려면 다음과 같이 to_datetime() 메서드를 사용할 수 있습니다.
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')위 코드에서 pd.to_datetime(df['date'], format='%Y-%m-%d')는 'date'열의 모든 값을 날짜/시간형으로 변환한 후 시리즈 객체를 반환합니다. 이 값을 다시 'date'열에 대입하여 'date'열의 데이터 타입을 날짜/시간형으로 변경합니다. 여기서 format 매개변수는 'date'열의 값이 어떤 형식으로 표현되어 있는지를 지정합니다. 위 예시에서는 '%Y-%m-%d' 형식으로 지정했으므로 'date'열의 값들이 'YYYY-MM-DD' 형식으로 표현되어 있다고 가정했습니다.
4.apply()
data = {'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'age': [23, 35, 27, 29, 31],
'score1': [80, 90, 75, 85, 95],
'score2': [85, 95, 70, 80, 90]}
df = pd.DataFrame(data)다음과 같은 데이터프레임이 있다고 가정해봅시다.여기서 'score1'과 'score2' 열의 값의 평균을 구해서 새로운 열 'score_mean'에 저장하려면 다음과 같이 apply() 메서드를 사용할 수 있습니다.
df['score_mean'] = df[['score1', 'score2']].apply(lambda x: x.mean(), axis=1)위 코드에서 df[['score1', 'score2']]는 'score1'과 'score2' 열에 해당하는 데이터프레임을 반환합니다. 이 데이터프레임에 apply() 메서드를 적용하면 각 행(row)에 대해 함수를 적용하게 됩니다. 여기서는 lambda x: x.mean() 함수를 적용해서 각 행의 'score1'과 'score2' 열의 평균을 구하도록 했습니다. axis=1 매개변수를 지정하여 각 행(row)에 대해 함수를 적용하도록 했습니다. 마지막으로 이 값을 'score_mean' 열에 대입하여 'score_mean' 열을 추가합니다.
간단하게 샘플 코드로 정리하고자 합니다.
import os
import pandas as pd
import numpy as np
if __name__ == '__main__':
print(f'{os.path.dirname(__file__)}')
#
df = pd.DataFrame( np.random.randn(5, 5),
columns=['A','B','C','D','E' ] )
# show all data
print(df)
# print #2 row
print(df.loc[2, :])
# Dataframe to List
rowList = df.loc[2, :].values.flatten().tolist()
print(rowList)
# subset dataframe to list
rowList = df.loc[2, ['A','E']].values.flatten().tolist()
print(rowList)[실행결과]
# show all data
print(df) A B C D E
0 1.736102 -1.477961 -1.179571 1.411220 -0.211700
1 0.175911 -0.518549 0.594174 0.333632 -1.579409
2 0.595619 -0.224543 -0.715213 -0.049334 -0.471737
3 0.639203 -0.451774 -0.009238 0.684090 -0.036995
4 -0.303029 -0.655539 -1.132769 0.485218 1.205955
# print #2 row
print(df.loc[2, :])A 0.595619
B -0.224543
C -0.715213
D -0.049334
E -0.471737
Name: 2, dtype: float64
# Dataframe to List
rowList = df.loc[2, :].values.flatten().tolist()
print(rowList)[0.5956188992136562, -0.2245426559477047, -0.7152127642656871, -0.049333965859220306, -0.4717365476151358]
# subset dataframe to list
rowList = df.loc[2, ['A','E']].values.flatten().tolist()
print(rowList)
[0.5956188992136562, -0.4717365476151358]
# 특정 컬럼을 기준으로 DF를 비교하여, 다른 ROW를 추출
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie', 'Dave', 'Eve'],
'Age': [25, 30, 35, 40, 45],
'City': ['New York', 'San Francisco', 'Los Angeles', 'New York', 'San Francisco']
})
# City 컬럼을 기준으로 중복되는 데이터를 제거합니다.
unique_cities = df['City'].unique()
# 다른 row를 저장할 빈 DataFrame을 생성합니다.
result = pd.DataFrame()
# unique_cities를 순회하면서 다른 row를 추출합니다.
for city in unique_cities:
temp_df = df[df['City'] == city]
if len(temp_df) > 1:
# City 컬럼이 같은 row를 비교합니다.
# 중복을 제외한 첫 번째 row와 다른 row를 찾아냅니다.
diff = temp_df.loc[temp_df.index.difference([temp_df.index[0]])]
result = pd.concat([result, diff])
# 결과를 출력합니다.
print(result)dataframe의 row와 column 수가 같다면, compare등의 함수를 사용하여 쉽게 되는데, row수가 다른 경우는 이 방법이 최선듯하여 공유 합니다.
간단하게 예제 코드를 기록하였습니다.
import pandas as pd
# 첫 번째 DataFrame 생성
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
# 두 번째 DataFrame 생성
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': [5, 6, 7, 8]})
# 두 개의 DataFrame을 key 열을 기준으로 merge
merged = pd.merge(df1, df2, on='key', how='outer', suffixes=('_left', '_right'))
# value_left 열과 value_right 열이 다른 행을 추출
diff_rows = merged[merged['value_left'] != merged['value_right']]
print(diff_rows)
프로그램 테스트를 진행 하다가 예상치 못한 동작이 발견되어, 원인을 파악해 보니, 공백 처리가 미진하게 되어 발생되었음을 확인하게되었습니다. 이 이슈는 정말 아주 아주 오랜(?)만에 경험하게 되었습니다.
공백(Blank)는 두가지 의미로 생각해야 합니다.
진짜 아무것도 없다? 아니면, 화면에 보이지 않는 어떤 값이 있는건지?
간단히 생각의 흐름대로 아래와 같이 정리하여 보았습니다.
1. 예제 데이타
- 기대한 데이타: 값이 없는 경우(ex: 공백 등) 모두 0으로 설정( dataframe = dataframe.fillna(0))
- 예상치 못한 데이타: 아래와 같이 0으로 변경되지 않고 빵구(?), 정체 불명의 공백이 그대로 있음
저 공백에는 머가 있는거지?
아이템 경험가중치
0 0
1 0
2 0
: :
60 0
61 0
62
63
64 0
65 0
66
67
68 0
: :
: :
106 0
107 0
108 0
109
110 0
111
112 0
: :
127 6,243,841
128 23,787,440
129 11,598,306
130 5,240,070
131 5,933,144
: :
: :2. 빵구(?) 정체 확인
2.1 접근1
- 아래와 같이 null 이 있는지 확인
print(expDf.info())
print(expDf.isnull())RangeIndex: 2690 entries, 0 to 2689
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 경험가중치 2690 non-null object
dtypes: object(1)
memory usage: 21.1+ KB
None
경험가중치
0 False
1 False
2 False
3 False
4 False
: :
: :
2688 False
2689 False- 위와 같이, 공백이 없다는 것을 확인함.
2.2 접근2
- 각 컬럼 값의 길이를 찍어 봄
print(expDf['경험가중치'].str.len())0 NaN
1 NaN
: :
61 NaN
62 2.0
63 2.0
64 NaN
65 NaN
66 2.0
67 2.0
68 NaN
: :
: :
108 NaN
109 2.0
110 NaN
111 2.0
112 NaN
: :
124 NaN
125 NaN
126 NaN
127 10.0
: :
2688 11.0
2689 11.0- 길이를 확인하여 보니, 어떤 값이 들어 가 있다는 것을 확신하게 됨
2.3 접근3
- 해당 행(62번행) hex값을 확인함
print(expDf['경험가중치'].iloc[62])
print(type(expDf['경험가중치'].iloc[61]))
print(type(expDf['경험가중치'].iloc[62]))
# str -> hex
# value = ''.join(format(ord(i), '08b') for i in expDf['경험가중치'].iloc[62])
#print(str(value))
print(expDf['경험가중치'].iloc[62].encode('utf-8').hex())<class 'int'>
<class 'str'>
c2a020- 값을 확인해 보면, 62번 행은 string 타입이고, 이 값의 hex값을 위와 같이 확인할수 있다.
그리고, hex값 20은 SPACE를 의미 한다는 것을 확인할수 있게 됨
3. 해결방법
- 원인 확인: 해당 공백이 SPACE에 의해서 발생했음을 확인함.
expDf['경험가중치'] = expDf['경험가중치'].replace(r'^\s+$', np.nan, regex=True)
expDf['경험가중치'] = expDf['경험가중치'].replace(np.nan, 0)- 'SPACE' 공백을 NaN으로 전환하고, 이 값을 0으로 바꿈
아이템 경험가중치
: :
59 0
60 0
61 0
62 0
63 0
64 0
65 0
66 0
67 0
: :정상적으로 결과를 나왔음을 확인
4. 결과
- NULL관련된 이슈는 참으로 오래된 이슈(?)여서 재밌기도 하였지만, 느닷없이 발생했을때는 좀 놀랐네요.
개발을 진행하다 보면, 두개의 리스트중 하나를 key로 하고, 나머지 하나의 리스트를 value 연결합니다.
이때, C++/Java/c#등의 언어 map을 사용하고, Python은 dictionary를 사용하게 됩니다.
Python은 다른언어에 비교해서 문법적으로 매우 직관적입니다. 대신, 다른 언어와 다르게 zip()함수를 사용합니다.
[코드예제]
keyList = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
valueList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pairDic = {key: value for key, value in zip(keyList,valueList)}
print(pairDic)
print(pairDic['j'])
print(pairDic['e'])[코드결과]
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10}
10
5
행(row)과 열(column) 형태인 datafram을 결합하기 위해서 concat() 함수를 사용합니다.
사용 방법은 매우 직관적이며 아래의 샘플코드를 한번 보시면 고등학생때 수업시간에 배운 집합을 생각하시면 매우 간단합니다.
1. 예제1
SampleDf1 = {'A': ['A1', 'A2', 'A3', 'A4'],
'B': ['B1', 'B2', 'B3', 'B4'],
'C': ['C1', 'C2', 'C3', 'C4'],
}
df1 = pd.DataFrame(SampleDf1)
print(df1)
SampleDf2 = {'A': ['A1', 'A2', 'A3', 'A4'],
'B': ['B1', 'B2', 'B3', 'B4'],
'C': ['C1', 'C2', 'C3', 'C4'],
}
df2 = pd.DataFrame(SampleDf2)
print(df2)(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
unionDf = pd.concat([df1, df2])(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
unionDf = pd.concat([df1, df2], ignore_index=True)- 인덱스 새롭게 설정함
(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
4 A1 B1 C1
5 A2 B2 C2
6 A3 B3 C3
7 A4 B4 C4
unionDf = pd.concat([df1, df2],axis=1)
print(unionDf)- 옆으로 데이타를 연결
(실행결과)
A B C A B C
0 A1 B1 C1 A1 B1 C1
1 A2 B2 C2 A2 B2 C2
2 A3 B3 C3 A3 B3 C3
3 A4 B4 C4 A4 B4 C4
unionDf = pd.concat([df1,df2],ignore_index=True).drop_duplicates(keep='first')
print(unionDf)# 중복행 제거: drop_duplicates() 사용
(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
unionDf = pd.concat([df1,df2],ignore_index=True).drop_duplicates(keep='last')
print(unionDf)(실행결과)
A B C
4 A1 B1 C1
5 A2 B2 C2
6 A3 B3 C3
7 A4 B4 C4
2. 예제2
SampleDf1 = {'A': ['A1', 'A2', 'A3', 'A4'],
'B': ['B1', 'B2', 'B3', 'B4'],
'C': ['C1', 'C2', 'C3', 'C4'],
}
df1 = pd.DataFrame(SampleDf1)
print(df1)
SampleDf2 = {'C': ['C1', 'C2', 'C3', 'C4'],
'D': ['D1', 'D2', 'D3', 'D4'],
'E': ['E1', 'E2', 'E3', 'E4'],
'F': ['F1', 'F2', 'F3', 'F4'],
}
df2 = pd.DataFrame(SampleDf2)
print(df2)
unionDf = pd.concat([df1, df2])
print(unionDf)(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
C D E F
0 C1 D1 E1 F1
1 C2 D2 E2 F2
2 C3 D3 E3 F3
3 C4 D4 E4 F4
A B C D E F
0 A1 B1 C1 NaN NaN NaN
1 A2 B2 C2 NaN NaN NaN
2 A3 B3 C3 NaN NaN NaN
3 A4 B4 C4 NaN NaN NaN
0 NaN NaN C1 D1 E1 F1
1 NaN NaN C2 D2 E2 F2
2 NaN NaN C3 D3 E3 F3
3 NaN NaN C4 D4 E4 F4
unionDf = pd.concat([df1, df2], ignore_index=True)
print(unionDf)(실행결과)
A B C D E F
0 A1 B1 C1 NaN NaN NaN
1 A2 B2 C2 NaN NaN NaN
2 A3 B3 C3 NaN NaN NaN
3 A4 B4 C4 NaN NaN NaN
4 NaN NaN C1 D1 E1 F1
5 NaN NaN C2 D2 E2 F2
6 NaN NaN C3 D3 E3 F3
7 NaN NaN C4 D4 E4 F4
unionDf = pd.concat([df1, df2],axis=1)
print(unionDf)(실행결과)
A B C C D E F
0 A1 B1 C1 C1 D1 E1 F1
1 A2 B2 C2 C2 D2 E2 F2
2 A3 B3 C3 C3 D3 E3 F3
3 A4 B4 C4 C4 D4 E4 F4
3.정리
세부적인 설명보다는 샘플코드와 실행결과를 보면 이해가 쉽게 될것으로 생각되어 코드와 실행결과를 남겼습니다.