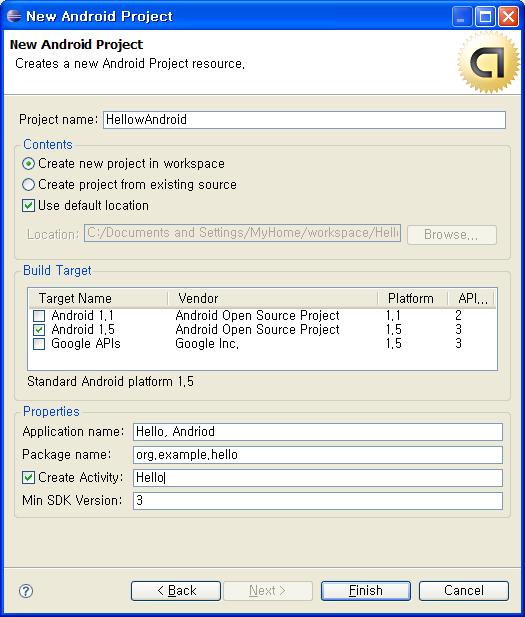
방법은 여러가지가 있겠지만, 대용량 분산과 QoS를 합리적 로직으로 풀어낸 부분이 너무나 마음에 드는 구조이고, service architecture는 개인적인 경험으로 봤을 때, 인증/권한 architecture중의 하나인 PKI Infrastructure와 유사해 보인다.
Google is well known for snatching up top-level talent, this holds true in Kenya as well. ICT groundbreaker Joe Mucheru heads up the Kenya office, and he’s surrounded by a team of smart young technologists. I had the chance to meet Isis Nyong’o (Strategic Parter Development Manager) while getting ready for Barcamp Nairobi, and then Chris Kiagiri (Tech Lead) and Mark de Blois (Geographic Supervisor) last week before I left.
Google Kenya is Different
I found out a couple of interesting points that make the Google Kenya office even more interesting than before. It turns out that there are 3 offices in Africa; Kenya, South Africa and Egypt. However, the office in Kenya is neither a sales office nor an engineering office, which makes it unique globally. In fact, it is the only “deployment office” worldwide. This means that the Kenya office can be used as a launch point for new ideas and is the central focal point for Google’s Africa strategy.
It came down to a choice between Senegal and Kenya – one French-speaking and one English-speaking, and both with a fairly well developed technology sector. Senegal had a direct transatlantic cable, but Kenya had the right people available. At Google it seems, finding the right personnel usually trumps about everything else.
Speaking of which, they’re still looking for the right people, not only in Senegal, but also in Nigeria, Ghana, Rwanda, Tanzania and Uganda. Unfortunately, Google HR seems to be geographically challenged, as jobs in Egypt are somehow not in Africa…
Dealing with a Slow Internet in Africa
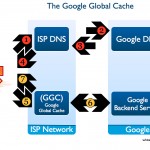
The Google Global Cache (GGC) was announced in May at the African Network Operators Group (AFNOG) conference in Morocco. In lieu of data centers in Africa, Google has created a strategy that is housed at major exchange points to serve Africa at the edge of Google’s network. Internal tests suggested at least 20% performance increase in high latency links, like East Africa.

[The top cycle (1,2,3 & 4) is how things normally work. The bottom cycle (5,6 &7) is where the changes are.]
It works like this. Once anyone within that exchange point’s sphere visits a webpage, the information is cached and it becomes much faster for anyone else visiting that website to access it. Pre-fetching of data also that improves performance over time, even for dynamic content.
This is an interesting strategy. It’s a win for ISP’s (less international traffic means lower costs), a win for end users (pages load faster), and a win for Google (faster, better usage).
The pilot in Africa was turned on in Kenya just 2 weeks ago. There are 17 international exchange points (IXP) in 15 African nations, so with a positive pilot in Kenya, this could soon be seen continent-wide.
Keep your ears open, there are hints of even more interesting stuff coming out of the Google Kenya office.
LG U+ 가입자의 경우 LG U+ Google Cache로 부터 어떤 흐름으로 동영상이 다운로드 되는지 설명드리도록 하겠습니다. 먼저 LG U+ Google Cache내에 사용자가 요청한 동영상이 있는 경우(Cache Hit)의 흐름을 알아보고, 이후 동영상이 없는 경우(Cache Miss)의 흐름에 대해서 살펴 보도록 하겠습니다.
LG U+ 회선을 통한 YouTube 다운로드
(1) LG U+ Google Cache에 동영상이 있는 경우 (Cache Hit)
LG U+ 망 내부에(LG U+ IDC;Internet Data Center에) Google Cache가 들어 있다는 점 외에는 지난 시간의 KT 그림과 동일한 구성입니다.

1.LG U+ 가입자가 브라우져에서 www.youtube.com을 입력하고, 단말에서 LG U+ DNS 서버로 DNS Query를 보냅니다. 반드시 LG U+ DNS일 필요는 없습니다. 어떤 DNS 서버이든 상관 없습니다.
2.그리고 LG U+ DNS는 YouTube 서버 주소 74.125.71.136을 가입자 단말로 전달합니다.
3.가입자는 Avatar 동영상을 클릭합니다.
4.이제 HTTP GET을 통해 Avatar 동영상 요청 메시지가 YouTube 서버로 전달됩니다.
5.이 대목이 아주 중요하니다! HTTP GET 메시지를 받은 YouTube 서버는 단말의 IP 주소 대역을 확인합니다. 이 경우 동영상을 요청한 가입자의 IP 주소 대역이 LG U+입니다. 그러면 YouTube 서버는 LG U+내에 위치한 Google Cache를 선택하여
6.그 hostname(o-o.preferred.lgupluswireline-gmp1.v9.lscache5.c.youtube.com)을 가입자 단말로 전달합니다.
7.가입자 단말은 hostname에 대한 DNS Query를 하고 (역시 DNS 서버가 LG U+ 일 필요는 없음)
8.그 응답으로 IP 주소 61.36.166.12를 받아 옵니다. 이 주소는 LG U+ 내의 Google Cache 주소입니다.
9.이제 단말에서 LG U+ Google Cache로 Avatar 동영상을 요청하고
10.여기서 또 중요! LG U+ Google Cache는 다시 HTTP GET을 보낸 단말의 IP 주소 대역을 확인합니다. 만약 이 주소 대역이 LG U+ 가입자 대역이 아니면 HTTP 302 Found 메시지를 단말로 보내어 미국에 있는 Google Cache로 붙도록 합니다(HTTP Redirect). 즉, 내 가입자 아니면 안받아 주겠다는 거죠. 위 경우는 LG U+ 가입자이므로 밑에 11번 단계로 넘어가게 됩니다.
11.이제 LG U+ Google Cache는 가입자가 요청한 동영상(Avatar)이 나한테 있는지(storage에 있는지) 확인합니다. 다행히 있습니다! (Cache Hit)
12.따라서 LG U+ Google Cache는 동영상을 가입자 단말로 전달합니다. RTT 10ms 이하입니다. 무지 빠르게 가입자 단말로 동영상이 전달됩니다
(2) LG U+ Google Cache에 동영상이 없는 경우 (Cache Miss)
이번 그림에서는 설명을 단순화 하기 위해 DNS flow는 제외 시켰습니다.

(2) LG U+ Google Cache에 동영상이 없는 경우 (Cache Miss)
이번 그림에서는 설명을 단순화 하기 위해 DNS flow는 제외 시켰습니다.
1.LG U+ 가입자가 YouTube 웹페이지에서 Avatar 동영상을 클릭합니다.
2.가입자 단말은 HTTP Get 메시지를 YouTube 서버로 보내고
3.YouTube 서버는 단말의 IP 주소를 확인하고, LG U+ 가입자 이므로
4.LG U+ Google Cache hostname(o-o.preferred.lgupluswireline-gmp1.v9.lscache5.c.youtube.com)을 단말로 전달합니다.
5.가입자 단말은 이제 LG U+ Google Cache로 Avatar 동영상을 요청하고,
6.LG U+ Google Cache가 단말 IP 주소를 확인하였더니 자사 가입자입니다.
7.이제 가입자가 요청한 Avatar 동영상의 캐싱 여부를 확인합니다. 그런데 그 동영상이 없습니다! (Cache Miss)
8.이제부터 시험을 통해 확인된 내용과 일부 추측을 기반으로 설명을 드리겠습니다. LG U+ Google Cache는 Avatar 동영상이 미국내 어느 Google Cache에 들어 있는지 알길이 없을 것 같습니다. 따라서 미리 configuration되어 있는 상위 Google Cache 서버로 HTTP Redirection을 시킵니다. 시험으로 확인하 결과 아래와 같이 hostname의 숫자값이 동일한 매핑 규칙을 발견할 수 있었습니다. 즉
•LG U+ Google Cache "o-o.preferred.lgupluswireline-gmp1.v9.lscache5.c.youtube.com"의 상위 Cache 서버는 -> 미국에 "v9.nonxt5.c.youtube.com"
•LG U+ Google Cache "o-o.preferred.lgupluswireline-gmp1.v12.lscache6.c.youtube.com"의 상위 Cache 서버는 -> 미국에 "v12.nonxt6.c.youtube.com"
9.가입자 단말은 LG U+ Google Cache가 알려준 v9.nonxt5.c.youtube.com으로 Avatar 동영상을 요청하고,
10.이 서버에도 해당 동영상이 없으면 다시 redirector.c.youtube.com으로 HTTP Redirection을 합니다. 추측컨데 redirector.c.youtube.com이 최상위에 위치한 서버로써 모든 동영상의 위치(어느 Cache 서버에 그 동영상이 있는지)를 관리하는 듯 합니다.
11.가입자 단말은 redirector.c.youtube.com으로 Avatar 동영상을 요청하고,
12.드디어 Avatar 동영상이 위치해 있는 Google Cache 서버의 hostname(o-o.preferred.lax04t01.v1.lscache6.c.youtube.com)을 받아 옵니다.
13.가입자 단말은 그 hostname으로 Avatar 동영상을 요청하고,
14.미국에 있는 Google Cache로 부터 동영상을 다운로드 받습니다.
여기서 그럼 LG U+ Google Cache 서버는 언제 Cache Fill을 하나? 라는 의문이 생기는데요. Cache Miss가 난 이후 다시 동일 동영상을 요청해 봤지만 여전히 미국에 있는 Google Cache로부터 다운로드 받는 것으로 보아, 각 Google Cache에는 "동일 컨텐츠를 몇번 이상 요청하면 Cache Fill한다"라는 식의 정책이 들어 있는 것으로 추측이 됩니다.
결언
위와 같이 미국에 있는 YouTube 서버 및 LG U+에 도입된 Google Cache는 HTTP GET 메시지을 보낸 단말 IP 주소 대역을 확인하여 어느 지역의 Google Cache를 통해 다운로드 받게 할지 결정합니다. 즉, KT 가입자는 KT IP 주소 대역을 사용하므로 DNS만 LG U+로 변경한다 해서 LG U+ Google Cache에 접속할 수는 없습니다. (그렇다고 KT 가입자가 단말의 IP 주소를 LG U+ 대역으로 바꾸면 라우팅이 안되어 아예 인터넷을 사용할 수 없게 되구요.)
이 말은 곧, LG U+ 가입자가 KT DNS를 사용해도 아무 문제 없이 LG U+ Google Cache를 통해 동영상을 다운로드 받게 됩니다.
마지막으로 한가지 더 말씀드리자면...
저희 회사가 LG U+ 기업용 회선을 사용하고 있습니다. 회사에서 확인을 해 보니, LG U+ 기업용 회선 가입자의 경우 LG U+ Google Cache로 부터 동영상 다운로드가 안되고, 그래도 RTT가 좀 짧은(100ms 정도) 홍콩에 위치한 Google Cache(o-o.preferred.hkg05s01.v20.lscache7.c.youtube.com)로 부터 동영상을 다운로드 받음을 확인하였습니다.
즉, 미국에 있는 YouTube 서버는
1) LG U+ 홈 가입자 IP 대역이면 LG U+ Google Cache를 선정해 주고
2) LG U+ 기업용 가입자 IP 대역이면 홍콩에 위치한 Google Cache를 선정
3) 나머지 경우(예. KT IP 대역이면) 미국에 위치한 Google Cache를 선정
[소스:http://whiteafrican.com/2008/07/04/google-kenya-and-the-google-global-cache/}
[소스:http://www.netmanias.com/bbs/view.php?id=blog&no=301'