'MINERVA/Python'에 해당되는 글 48건
- 2022.05.31 :: [Python] 튜플(tuple) 객체 정리
- 2022.05.27 :: [Python] 시퀀스 자료형[Sequence types]
- 2022.05.23 :: [Python] Object 비교
- 2022.05.20 :: [Python] 객체 종류(mutable,immutable) vs 메모리(memory)
- 2022.05.12 :: [Python] Data Types, Object Types
- 2021.09.07 :: [Python] 디버깅 함수: dumpcode
- 2021.09.07 :: [Python] 기초 함수 정리
- 2021.09.05 :: [Python] 문자열 출력: 3가지 방법
튜플(tuple)을 간단히 말하면 변경할수 없는(immutable) 시퀀스 자료형(sequence type)입니다.
그런데, 앞에서 학습한 리스트(list)가 있는데 왜? 튜플(tuple)이 있을까?
그 이유는, 튜플은 리스트에 비해서, 가볍고(즉, 빠르다)고 메모리를 작게 사용합니다.(이 부분은 별도로 정리하겠습니다.)
튜플(tuple) 사용 용례를 정리하면 다음과 같습니다.
#########################################
# [튜플(Tuple) 실습]
# 1) sequence types 실습: indexing, slicing, concatenating, iterating, size
# 2) 왜? Tuple을 사용할까? 리스트로 다하면 되는데?
# -> 메모리를 절약하고, 성능이 더 좋다.
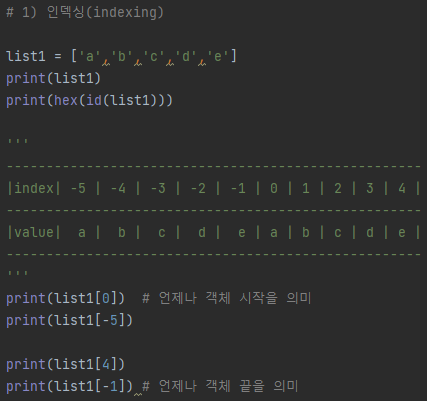
###### 1) 인덱싱(indexing)
print(aTuple)
print(aTuple[0]) # 0 인덱스: Tuple 객체의 맨 처음
print(aTuple[-1]) # -1 인덱스: Tuple 객체의 맨 마지막
# tuple안의 tuple: 기준값을 저장할때 많이 사용
dTuple = ( (1,2,3), ('a','b','c'))
print(dTuple)
print(dTuple[0])
print(dTuple[1])
print(dTuple[0][1])
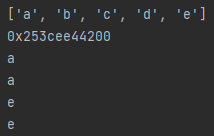
print(dTuple[1][0])[결과]
(1, 2, 3, 4, 5, 6, 7, 8, 9)
1
9
((1, 2, 3), ('a', 'b', 'c'))
(1, 2, 3)
('a', 'b', 'c')
2
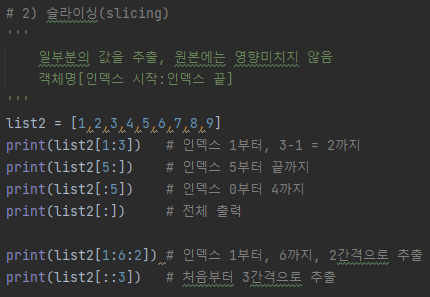
a# 2) 슬라이싱(slicing)
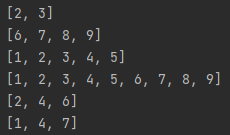
print(aTuple[1:]) # 인덱스 1부터 마지막까지
print(aTuple[:4]) # 인덱스 처음(0)부터 인덱스 4까지
print(aTuple[1:3]) # 인덱스 1부터 인덱스 5까지
print(aTuple[:]) # 인덱스 처음 마지막까지
print(aTuple[1:9:2]) # 인덱스 1부터, 9까지, 2간격으로 추출[결과]
(2, 3, 4, 5, 6, 7, 8, 9)
(1, 2, 3, 4)
(2, 3)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
(2, 4, 6, 8)# 3) 연결(concatenating)
bTuple = ('a','b','c','d')
cTuple = aTuple + bTuple
print(cTuple)[결과]
(1, 2, 3, 4, 5, 6, 7, 8, 9, 'a', 'b', 'c', 'd')# 4) 반복(iterating)
print(bTuple*3)[결과]
('a', 'b', 'c', 'd', 'a', 'b', 'c', 'd', 'a', 'b', 'c', 'd')# 5) 크기(sizing)
print(len(bTuple))[결과]
40. 정의
순서(번호)를 붙여 나열되어 있는 객체를 의미. 여기서 순서(번호)를 인덱스(index)라고함
각각의 요소(element) 또는 데이터(data)들이 연속적으로 이어진 자료형을 의미하며, 각, 데이터(data)에는 순서(번호)를 붙여 나열함
다시 정리하면,
시퀀스 자료형으로 만든 객체를 시퀀스 객체라고 하며 시퀀스 객체 안에 들어있는 값들을 요소라고 부릅니다.
1. 시퀀스 자료형 종류
list, tuple, 문자열, range, bytes, bytearray
2. 시퀀스 자료형 특성
1) 인덱싱 (indexing)
- 인덱스를 통해 값에 접근가능(인덱스는 0부터 시작)
2) 슬라이싱 (slicing)
- 일부분의 값을 얻을 수 있음, 원본에는 영향미치지 않음
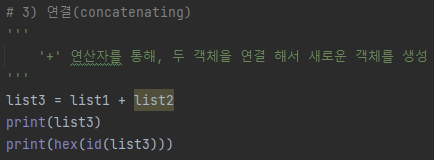
3) 연결(concatenating)
- '+' 연산자를 통해서 두 객체를 연결해서, 새로운 시퀀스 객체를 생성
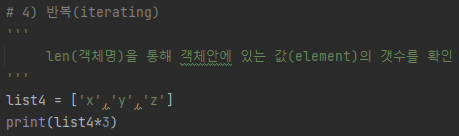
4) 반복
- '*' 연산자를 통해서 객체를 원하는 만큼 반복 가능
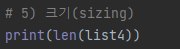
5) 크기
- len(객체명)을 통해 객체안에 있는 값(element)의 갯수를 확인
3. 예제



z파이썬은 모든 것이 Object이다. 그리고, Object를 비교는 2가지 관점으로 고려된다.
1) 같은 Object인가?(같은 인스턴스인가?) --> 비교연산자: is
2) Object value 값이 같은가? --> 비교연산자 ==
예제)
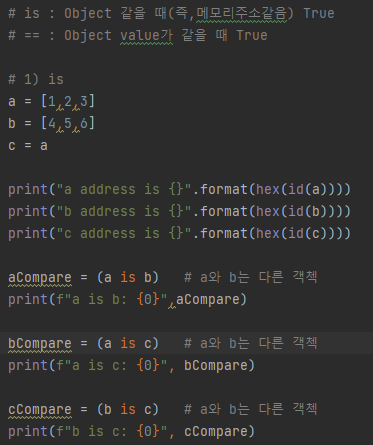

# 예제1 과 결과1를 보면, "is" 비교 연산자는 object의 id, 즉, memory address가 같으면 True를 반환함을 확인

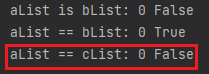
# 예제2 과 결과2를 보면, "==" 비교 연산자는 object가 가지고 있는 실제 value를 비교하여 같으면 True를 반환
# 여기서 전제조건은 같은 Data typs이여야 함
저의 경우에는 C/C++, Java 개발 언어를 선경험하고, Python을 접하게 되었을때 객체 종류(mutable,immutable)에 대한 부분은 많이 낯설게 느껴지는 부분이었습니다. 그래서, 초기에 이 부분에 많은 시간을 할애하여 공부하였습니다.
저는 아래의 두줄에 대한 내용을 간단히 정리하고자 합니다.
"파이썬의 모든것은 객체(object) 이고, 객체는 두가지(mutable vs immutable)로 분류된다.
또한, 객체는 나타내는 변수는 값(value)에 대한 참조(reference)이다."
참고로, 객체는 class라고 기능과 다양한 데이터의 조합이고, 이 클래스의 인스턴스(instance)를 객체(object)라고 합니다.
인스턴스란 class가 메모리의 영역에 할당되었다는 것을 의미함
1. 기본적인 접근
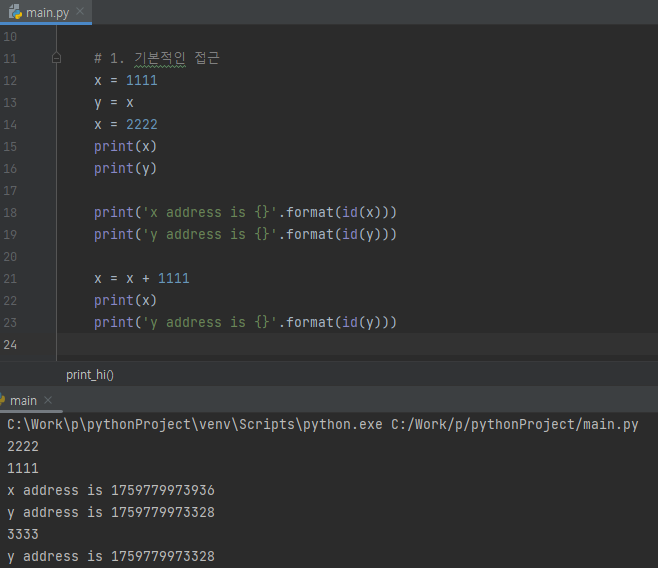
위의 예제와 실행결과를 간단히 보면, 변수 y에 변수 x값을 넣고, 변수 x의 값을 변경하였습니다. 이때, 마다 객체의 주소를 확인해보면, 매번 다른것을 확인 할수 있습니다. 이것은 매번 객체가 생성되었다는 것을 의미합니다.
개인들마다 결과를 보고 당연(?)하게 또는 이건 머지(?)하고 느끼는 분이 있을 듯합니다.
아마, 당연하게 느끼시는 분들은 x 와 y가 메모리의 다른 영역에 객체가 생성다고 느끼시는 분들이고, 의문을 가지시는 분들은 메모리 레퍼런스(reference) 참조를 왜 하지 않지? 라고 생각하시는 분들일 것입니다.
제가 여기서 중요하게 생각해봐야 할 부분은 객체의 ID, 주소가 계속 바뀌고, 즉, 메모리에 새로운 객체가 매번 생성된다는 의미 입니다. 이것은 저와 같은 c/c++ 개발자에게 객체 생성은 많은 비용(cost)이 든다고 배운 사람에게는 매우 금기시 되어 있는 부분입니다.
참조: Python은 GC(가비지 컬렉터)가 주기적으로 객체를 해제합니다.
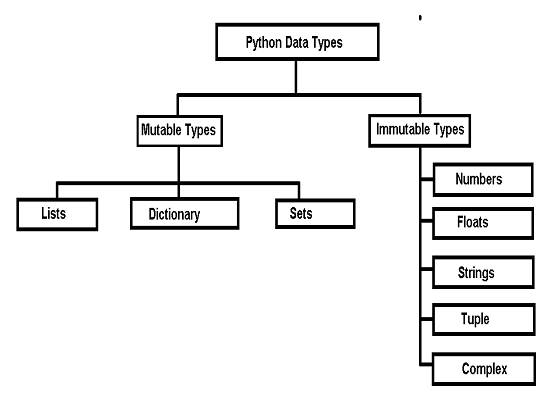
2. mutable(가변) vs immuable(불가변) 객체
개인적으로 성능과 효율성 이슈로 Python 창조자는 객체를 아래의 기준으로 2가지로 분류하였다고 생각합니다.
# mutable(가변) 객체: 값 변경시 객체 ID(즉, 메모리 주소)가 변경되지 않는, 즉 생성된 처음 위치에서 변경가능
# immuable(불가변) 객체: 값 변경시에 새로운 객체를 생성, 즉 새로운 객체 ID(즉, 메모리 주소)를 가지게 하였습니다.
객체분류: https://choiwonwoo.tistory.com/entry/Python-Data-Types-Object-Types?category=969492
[Python] Data Types, Object Types
1.기본적 오브젝트 분류 2. 객체 종류 - 파이썬의 모든 변수는 객체의 인스턴스다. 그리고, 객체는 2종류로 구분(1. Mutable, 2. Immutable)된다. - 객체가 인스턴스화될 때마다 고유한 개체 ID가
choiwonwoo.tistory.com
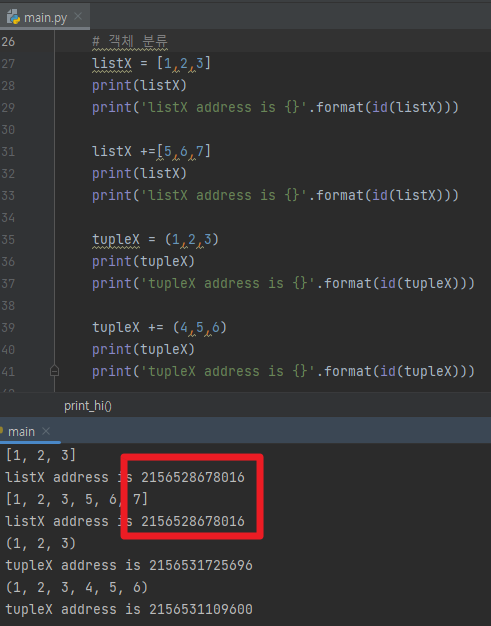
예제를 보면, mutable 객체인 listX와 immutable 객체를 생성하고 값을 추가하는 같은 작업을 하지만, 메모리를 관리하는 부분이 확실하게 다름을 확인할수 있습니다.
3. 결론
간단하게 파이썬에서 메모리 관점을 가지고 변수를 생성 및 변경시 내부적으로 어떻게 동작하는 방법에 대해서 정리하였습니다. 이 부분은 심각하게 생각하지 않고 작업은 가능하지만, 실질적으로 프로젝트 결과물에 대한 성능평가시 큰 차이를 보이게 할 수 있습니다.
1.기본적 오브젝트 분류
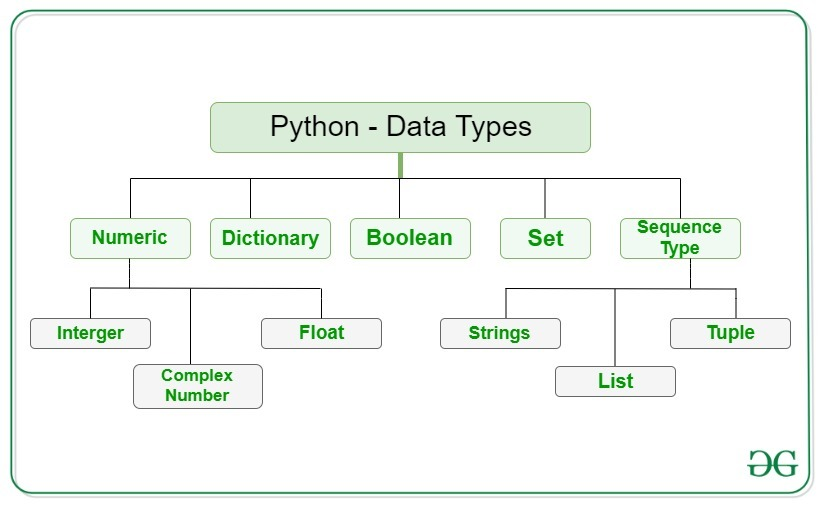
2. 객체 종류
- 파이썬의 모든 변수는 객체의 인스턴스다. 그리고, 객체는 2종류로 구분(1. Mutable, 2. Immutable)된다.
- 객체가 인스턴스화될 때마다 고유한 개체 ID가 할당되고, 객체 유형은 런타임에 정의되며 이후에는 변경할 수 없습니다. 그러나 변경 가능한(mutable) 객체인 경우 상태가 변경될 수 있습니다.
- 변경 가능한 객체는 상태나 내용을 변경할 수 있고, 변경할 수 없는 객체는 상태나 내용을 변경할 수 없습니다.
3. WHY?
- 호기심? 파이썬을 만든 사람들은 왜? 객체 2가지로 분류를 하였을까? 답: 속도와 비용 때문이다.
(이 부분에 대해 기술적으로 좀더 깊게 보고자 한다면, 얕은 복사(shallow copy) 와 깊은 복사(deep copy)에 대해서 보면 더 이해가 잘 됩니다.)
- 가변(mutable) 객체와 불변(immutable) 객체는 파이썬에서 다르게 처리됩니다.
변경할 수 없는 개체는 액세스가 더 빠르고 복사본을 생성해야 하기 때문에 변경 하는 데 비용이 많이 듭니다.
반면 가변 객체는 변경하기 쉽습니다.
4, 예제



5. 정리
- 개체의 크기 또는 내용을 변경해야 하는 경우 가변 개체를 사용하는 것이 좋습니다.
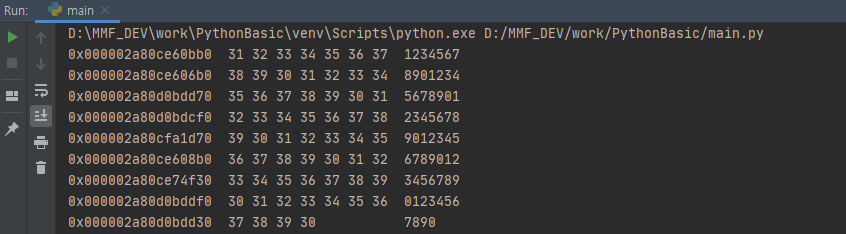
C/C++ 에서 사용하던 dumpcode(https://choiwonwoo.tistory.com/entry/%EB%94%94%EB%B2%84%EA%B9%85-3264-bits-dumpcodeh?category=267468) 함수를 Python에서 사용가능하게 바꾸어 보았습니다.
nMaxLineLen만 조절하셔서 사용하시면 됩니다.
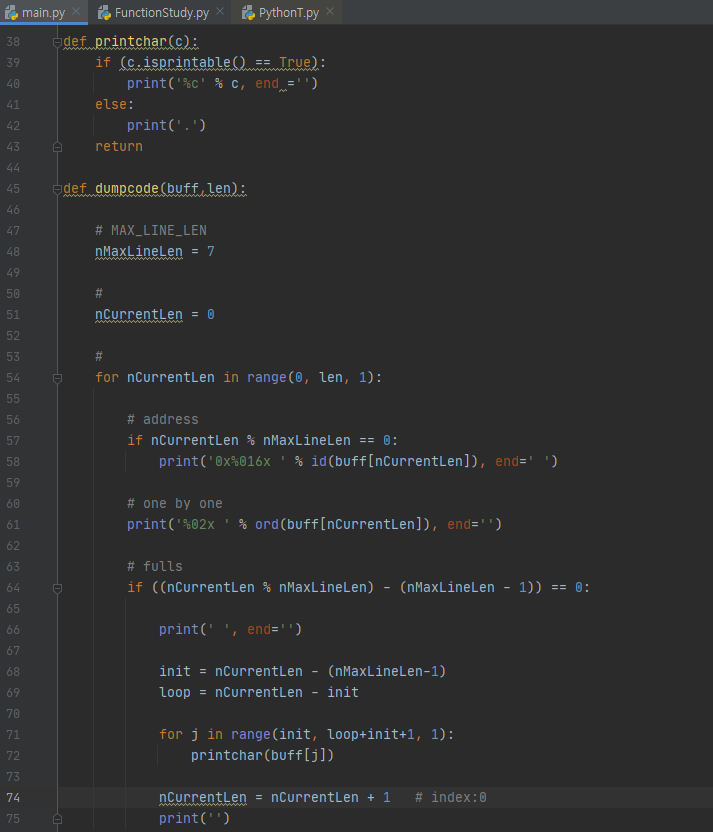
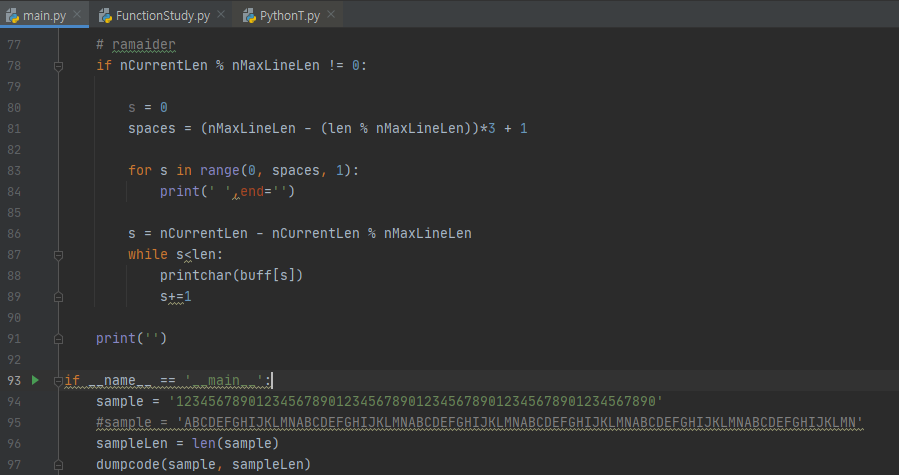
[사용결과]
##################################
# id(x): 객체(x) 주소(address) 확인
##################################
name = 'Python'
print(f'My name is {name} and object id is {id(name)}')
# passed by Assignment!!!(추후 정리)
obj_copy = name # passed by Assignment(o) call by reference(x) call by value(x)
print(f'My name is {obj_copy} and obj_copy id is {id(obj_copy)}')
#################################################
# type(x): 객체(x) 타입(type) 확인
# immutable objects: int, float, string, tuple
# mutable objects: list, dict, set
#################################################
age = 18
colors = ('red','blue','yellow')
print(f'type is {type(name)}')
print(f'type is {type(age)}')
print(f'type is {type(colors)}')
########################################################
# len(x): x 길이(문자열) 또는 원소의 갯수(tuple,list, dic...
########################################################
print(len(name),len(colors))
##################################
# eval(x): 식(x) 결과를 반환
##################################
a = eval ('"hello" + "python"')
b = eval ('100+40')
c = eval ('len(colors)')
print(f'results are {a}, {b},{c}')
최근 프로젝트를 완료하면서, 개인적으로 다시 한번 파이썬(Python)에 대한 정리 필요성을 느끼게 되어 해당내용을 하나씩 기록하고자 합니다.
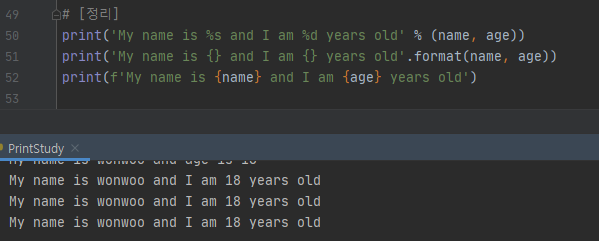
프로그래밍 언어를 공부시 개인적으로 제일 먼저 친해져야 하는 명령어가 출력문이다. 그 이유는 당연히 백문이 불여일견이 듯이, 백문이 불여일타의 첫시작이 출력문이기 때문이다.
# 문자열(string) 출력
print('Maing M&F')
# 문자열 포매팅(string formatting): 문자열의 원하는 위치에 변수값을 출력하는 것을 의미함
# 1) % 사용(서식문자): 정수(%d), 문자열(%s), 실수(%f), 문자(%%)...
str_sample1 = 'Hello %s' % 'Python'
print(str_sample1)
str_sample2 = 'My age: %d' % 18
print(str_sample2)
number = 1004
str_sample2 = 'My happy nummber : %d' % number
gifts=['bag','money','travel']
for gitf in gifts:
print('My gift is %s' % gitf)
# 인자가 두개 이상인경우: ()를 사용
str_sample3 = 'my name is %s and age is %d' % ('M&F',18)
print(str_sample3)
## 단점: formatter에 대응되는 데이터 타입을 정확히 알아야 하고,
## 코드가 길어지면 가독성이 떨어짐
# 2) str.format 사용(Python 3이상 부터 지원)
str_sample4 = 'Python version {}'.format(3)
print(str_sample4)
str_sample5 = 'My name: {}'.format('wonwoo')
print(str_sample5)
# multiple arguments
str_sample6 = 'My name is {0} and my age is {1}'.format('wonwoo',18)
print(str_sample6)
## 단점: 긴 문자열 처리 및 여러인자 일때 너무 문자열 길이가 길어지는 느낌!
# 3) f-string(Python 3.6이상 부터 지원)
name = 'wonwoo'
str_sample7 = f'My name is {name}'
print(str_sample7)
age = 18
str_sample8 = f'My name is {name} and age is {age}'
print(str_sample8)
## 정리: f-string이 가장 직관적이다. 사용하기 쉽다. 또한 속도 면에서도 가장빠르다.