
'Story List'에 해당되는 글 180건
- 2013.06.29 :: [Unity3D] NGUI: Next-Gen UI
- 2013.06.29 :: [Unity3D] EZGUI vs NGUI
- 2012.01.17 :: [(TIP) C++] Adding Console I/O to a Win32 GUI App
- 2011.12.03 :: [Paxos] Ring-Paxos: A High-throughput atomic broadcast protocol
- 2011.11.30 :: [PAXOS] Paxos made code
- 2011.11.30 :: DOS 명령어
- 2011.11.30 :: Utility to generate Visual Studio solution file for a group of projects
- 2011.11.29 :: [Window] 최대 오픈 세션 수 확인
- 2011.11.28 :: [Serialization/Deserialization] Protocol Buffers, Avro, Thrift & MessagePack
- 2011.11.28 :: [NoSQL] A comparison among NoSQL DBs
아래의 사이트에 가면, Free version의 NGUI를 구할수 있고, 사용 동영상을 볼수 있다.
http://forum.unity3d.com/threads/114833-NGUI-(Next-Gen-UI)-demo-amp-final-feedback-request
Choosing GUI framework for your Unity3D Project: EZGUI vs NGUI, Part I
The following post might be helpful for those standing on the crossroad which GUI framework to go with in Unity project. Among lots of more or less advanced 3rd party options there are just two which can be seriously considered: EZGUI and NGUI. I’ll clarify major differences I’ve noticed in my experience working with both of them.
EZGUI and NGUI provide great features for making in-game UI easily and efficiently. However they use different implementation approaches. EZGUI comprises lots of instruments and controls with plenty amount of settings, so you can tweak almost every parameter of any UI element. In opposite, NGUI provides lots of small components and I like its minimalism, short, clean and understandable code. Both EZGUI and NGUI target “1 draw call for UI” and they’ve got very close. Of course “one-draw call for UI” isn’t the main concern, but why not to have such a great addition to your well-structured and optimized code.
The following table contains a comparison of both frameworks with features I find important:
|
| |
Pixel perfect | Scale of controls is adjusted automatically once on a scene start. Note: it has issues losing render camera reference when instancing UI as a prefab | Scale of controls is adjusted automatically every time resolution changes. Also has ability to apply half-pixel-offset |
WYSIWYG | Generates ordinary gameobject with geometry, so everything is visualized by Unity itself | Uses several ways of visualization: “geometry” and “gizmos”, since all UI elements are a part of a single mesh |
Access from code | Methods from a specific controller-script are linked with control events. There can be some issues with instancing objects and losing references. Another way –using delegates can be more convenient in some cases | Similar as EZGUI, but here you have helper components, such as UIButtonMessage, which send specified message to a gameobject (or to itself, if target is null), on selected type of interaction. Also you can access to last used control through static variables such as UICamera.lastHit or UICheckbox.current |
Ease of controls creation | Empty GameObject is created and attached with necessary components | Provides handy wizards for creating all kind of controls. |
Workflow speed | Smooth, but slow. Searching scripts which aren’t included in common menus, adjusting tons of settings, fixing broken atlases and lost camera references (most likely I’m not the only one who experienced these issues) | Supersonic! Just a little slowdown when creating atlases for sprites in the beginning, and then pure enjoyment of future process! |
Drag and Drop | Both frameworks have this feature. Just a little note: any object in NGUI with a collider can be draggable | |
Atlases creation | Atlas has to be recreated every time you want to add/change an image in it. EZGUI can scan all objects, even in a project folder, find all using the same material and then regenerate the atlas. This process takes lots of time and you should be very accurate not to break something | Atlas can be managed in two ways: either using fast and handy Atlas Maker to add, delete or modify images in atlas or managing sprites in atlas already created via Atlas prefab inspector |
Panels switching | Making menus with switching panels has never been easier due EZGUI’s powerful abilities | Panels can be switched easily as well, but some additional scripting is required. Panels can be switched through animations and helper components, but I haven’t found any direct way to enable one and disable another panel |
Additional stuff | Since EZGUI is based on Sprite Manager, classes (e.g. Sprite etc.) can be quite useful in 2D games for environment creation, backgrounds etc. | Sprites can be used, however with some restrictions like any control must have a parent like panel or UIRoot. |
And here is a comparison by controls implemented in the frameworks.
Control | ||
Label | ||
Sprite | ||
Sliced sprite | ||
Tiled sprite | ||
Filled sprite | ||
Simple button | ||
Image button | ||
Toggle button | ||
Radio button | ||
Checkbox | ||
Progress bar | ||
Slider | ||
Input | ||
DropDown list | ||
Scrollable lists |
I was really excited with Sliced Sprite from NGUI. When there is an objective to create a resizable window that should be pixel-perfect in different sizes, have a frame outside of it and be filled with a pattern - that’s exactly when Sliced Sprite can manage everything, just specify areas on texture to be used as a frame, corners and filling.
Tiled Sprite can be implemented manually with EZGUI, however it won’t be so easy. Tiled sprite always stays pixel-perfect, and it tiles the texture you’re using when scaling. That’s very handy for creating backgrounds for example.
NGUI extends Unity with a bunch of useful hotkeys which are really nice-to-have, e.g. Ctrl+Shift+N to add new empty GameObject as a child to selected one, hotkey for toggling gameobject’s activity, handy buttons for resetting transform’s position, rotation and scale.
Both frameworks are provided with detailed documentation describing every script, every component, property or method. Additionally, NGUI is shipped with a lot of step-by-step tutorials, video and write-up lessons for beginners.
EZGUI is based on Sprite Manager 2 (developed by Above and Beyond Software). SM2 provides features for creating 3D mesh sprites, customizing and changing their parameters in runtime, as well as creating texture atlases, so that all sprites in a scene are a part of single batch and are drawn in one draw call.
And here’s my subjective comparison of these both frameworks:
|
| |
Usability |
|
|
Functionality |
|
|
Flexibility |
|
|
Reliability |
|
|
Extensibility |
|
|
…that means I like NGUI much more, however I haven’t described another very important difference between NGUI and EZGUI - the way of working with them. I’ll demonstrate it in my next post, stay tuned.
Choosing GUI framework for your Unity3D Project: EZGUI vs NGUI, Part II
As a follow-up to «Choosing GUI framework for your Unity3D project: EZGUI vs NGUI, Part I» here is another post comparing these both frameworks by workflows. They are quite different, probably when you realize it with this small example how to create a simple button, you will make your decision more confidently which framework to choose in your project.
Creating simple button with EZGUI
First of all let's create an orthographic camera in UI layer that will render UI-stuff only: GameObject -> CreateOther -> Camera and set it up as shown below:

You see I’ve attached UIManager component.
Create an empty GameObject called “Button” and attach Button component to it (“Component/EZ GUI/Controls/Button”). The script needs to be set up as well. Assign UI Camera in Render Camera slot, and check Pixel Perfect checkbox (Auto Resize will be checked automatically). And here is one of the most annoying disadvantages of EZGUI – when instantiating UI element as a prefab, there’s no guarantee Render Camera will be assigned correctly.
We will also need several button images for all button states: Normal, Over, Active, Disabled

Next, you will need to create atlas for button states. Just press this little gear and select “Build Atlas“

And here is the texture:

Note that atlas can contain not only states for single button – but for all the elements in your entire UI. But I would highly recommend sorting them by screens, like start screen elements in one atlas, settings screen in another. I like this way, because you won’t load memory with redundant atlases.
Now let’s make it working. It’s quite simple with EZGUI: just specify GameObject that has a script with a method that will be called when button is pressed.
Here’s the script that we have to attach to a “controller” GameObject.


Then configure the button: set controller GameObject in “Script With Method To Invoke” slot, specify method name in “Method To Invoke” field and select “When To Invoke” option.

Now if you click “Play” you will get fully functional button. Here we go…

And here is just a little tip. Attach EZ Screen Placement component to your button and it will be placed on screen just the way you need. For example you can stick your button with the top right corner of screen, or stick with some object, and it will maintain constant pixel offset in screen coordinates. Again be very careful with Render Camera. This is the first point you need to check if you see that your elements are moved to incorrect position or have a wrong scale. Also this component stops working in editor mode when you have it on prefab instance and click “apply” button – just click “Play” and then “Stop” to fix this.
Creating simple button with NGUI
Basically, both EZGUI and NGUI work with similar principle – generating meshes, generating UV coordinates and applying textures automatically. However NGUI’s “Button” doesn’t actually mean what we used to think. “Button” is everything in the scene that has a collider attached and is visible by camera having UICamera component, so this pseudo-button object can receive events, generated by UICamera. Here’s the list of all events.
When you see UIButton* (e.g. UIButtonColor) component, it does not mean that it has to be attached to something like a button (well, you won’t even find UIButton component in the list of scripts). Instead, it can be attached to ANYTHING that has a collider, for example – UICheckbox, and your own script, attached to this checkbox, will receive all the events from the list. Well, UICheckbox is just an example, but even a sphere with a collider can receive events! (It can be seen in one of examples provided by Tasharen Entertainment)
Now let’s do the same job using NGUI and start with some preparations. You need to create atlas for UI. In comparison with EZGUI – NGUI atlas is not just a texture – it’s a prefab that contains all information about sprites. It can be easily created using Atlas Maker.

By clicking “Create” button, wizard creates new material and prefab that will store all required information about atlas and sprites.

Great advantage of NGUI atlas is a possibility of adding and deleting images from atlas without rebuilding it totally. As you can see below, all you need to do is just select textures you want to add/update. In this case you see four new textures will be added to the atlas TestAtlas.

After adding images to atlas, you will be able to add, delete, and modify them at any time which is cool I think. The only thing I miss here is forcing creation of square atlases, which is required for PVRTC compression on mobile devices.

Atlas prefab can be edited from its inspector, where you can add, delete and setup sprites, with real-time preview of what you are doing.

So, when you’re finished with sprites, you can go ahead to creating your UI.
Create a base for the future UI. NGUI -> Create new UI. UI Tool opens up.
Just set a layer where UI will be rendered and a camera you’re going to use.

You will see the following hierarchy:

- “UI Root” is responsible for scaling the entire UI, to maintain its screen size when changing resolution.
- “Camera” renders UI geometry (btw, this geometry is handled by UIDrawcall script). It also sends events to objects.
- “Anchor” is used for placing widgets in correct positions, add half-pixel offset to all UI (you can read about half-pixel and half-texel offsets here), and it also can be used to stretch sprites to fill entire screen on different resolutions, e.g. to be used as tiling background.
- “Panel” groups UI objects (widgets) together and shows some debug information about widgets it contains. Also it has clipping ability to be used in scrollable lists.
Next step – creating widgets. “NGUI -> Create a Widget” opens Widget Tool. In order to create a widget of any type you need to specify an atlas where required sprites will be taken from, widget template – in our case it would be “Image Button”, that works quite similar to EZGUI’s button, setup images needed for three button states – normal, hover and pressed (I’m not sure why, but there’s no disabled state), and press “Add To” button.

That’s it, you already have you button! Just hit play and check it out!

And the last step – the button interaction with scripts. Attach “UI Button Message” component to the button. It allows calling methods in the script attached either to a button GameObject or any custom GameObject, specified in “Target” slot. If target GameObject isn't set, the button GameObject itself will be assigned as Target automatically.

You can see UIButtonMessage component on the screenshot, with Function Name specified – the name of method that will be called on a specific event (check “Trigger” variable).

Then, we press our button and here’s it:

Finally EZGUI or NGUI?
Personally I stick with NGUI that attracts with its minimalism, short, clean and easy-understandable code, stability and optimization. I really hope these posts were helpful for you. Please put comments, ratings and suggest what to add\improve, I’ll be able update this post later.
[source: http://blog.heyworks.com/choosing-gui-framework-for-your-unity3d-project-ezgui-vs-ngui-part-i/]
1) 콘솔창 사용
http://www.halcyon.com/~ast/dload/guicon.htm
http://www.codeproject.com/KB/debug/mfcconsole.aspx
2) log4xx를 사용
기본기능으로 console기능 지원도 하지만, 로그에 대한 뷰여가 좋은 것들이 많아 콘솔과 같은 느낌을 준다.
cf) Unix/Linx에서 지원하던 tail이 윈도우로 mtail이라고 있지만, 내부 버퍼, 그리고 UI가 아직은 비호감이다.
http://wn.com/Paxos_algorithm
현재 4번째....반복중..
분산을 공부하다보면 나오는 필수적인 개념으로 보인다.
하나씩 돌파 해보자.
아래 논문부터...
 marco.pdf
marco.pdfhttp://www.inf.usi.ch/faculty/pedone/MScThesis/marco.pdf
1. 도스 명령어를 사용하여 폴더 구조를 보기
> tree /f
> tree /a
> dir /s \wonwoo.txt
[ /s는 현재 디렉토리와 하위 디렉토리 포함]
[ \ <== root 디렉토리]
3. 특정 디렉토리 찾기
> dir /s /a:d \wonwoo*
[wonwoo라는 이름을 가진 모든 디렉토리 찾기]
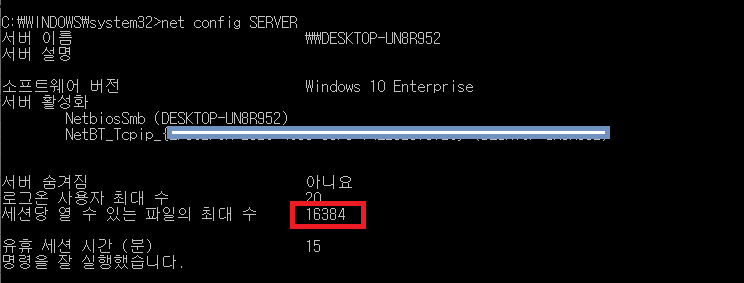
유닉스/리눅스에서는 다양한 방법으로 File descriptor(socket descriptor) 수 확인과 기동중인 프로세스가 점유중인 자원을 확인할 수 있다. 윈도우에도 똑 같은 기능이 있다고 생각되어 방법을 찾아 보았다.
방법:
이 명령어 실행하면, 시스템의 최대 File descriptor 수와 세션당 오픈할수 있는 최대 File descriptor수를 확인할수 있다. (이 명령어는 유닉스의 ulimit -a와 유사하다. )
Protocol Buffers, Avro, Thrift & MessagePack
 Perhaps one of the first inescapable observations that a new Google developer (Noogler) makes once they dive into the code is that Protocol Buffers (PB) is the "language of data" at Google. Put simply, Protocol Buffers are used for serialization, RPC, and about everything in between.
Perhaps one of the first inescapable observations that a new Google developer (Noogler) makes once they dive into the code is that Protocol Buffers (PB) is the "language of data" at Google. Put simply, Protocol Buffers are used for serialization, RPC, and about everything in between.
Initially developed in early 2000's as an optimized server request/response protocol (hence the name), they have become the de-facto data persistence format and RPC protocol. Later, following a major (v2) rewrite in 2008, Protocol Buffers was open sourced by Google and now, through a number of third party extensions, can be used across dozens of languages - including Ruby, of course.
But, Protocol Buffers for everything? Well, it appears to work for Google, but more importantly I think this is a great example of where understanding the historical context in which each was developed is just as instrumental as comparing features and benchmarking speed.
Protocol Buffers vs. Thrift
Let's take a step back and compare Protocol Buffers to the "competitors", of which there are plenty. Between PB,Thrift, Avro and MessagePack, which is the best? Truth of the matter is, they are all very good and each has its own strong points. Hence, the answer is as much of a personal choice, as well as understanding of the historical context for each, and correctly identifying your own, individual requirements.
When Protocol Buffers was first being developed (early 2000's), the preferred language at Google was C++ (nowadays, Java is on par). Hence it should not be surprising that PB is strongly typed, has a separate schema file, and also requires a compilation step to output the language-specific boilerplate to read and serialize messages. To achieve this, Google defined their own language (IDL) for specifying the proto files, and limited PB's design scope to efficient serialization of common types and attributes found in Java, C++ and Python. Hence, PB was designed to be layered over an (existing) RPC mechanism.
 By comparison, Thrift which was open sourced by Facebook in late 2007, looks and feels very similar to Protocol Buffers - in all likelihood, there was some design influence from PB there. However, unlike PB, Thrift makes RPC a first class citizen: Thrift compiler provides a variety of transport options (network, file, memory), and also tries to target many more languages.
By comparison, Thrift which was open sourced by Facebook in late 2007, looks and feels very similar to Protocol Buffers - in all likelihood, there was some design influence from PB there. However, unlike PB, Thrift makes RPC a first class citizen: Thrift compiler provides a variety of transport options (network, file, memory), and also tries to target many more languages.
Which is the "better" of the two? Both have been production tested at scale, so it really depends on your own situation. If you are primarily interested in the binary serialization, or if you already have an RPC mechanism then Protocol Buffers is a great place to start. Conversely, if you don't yet have an RPC mechanism and are looking for one, then Thrift may be a good choice. (Word of warning: historically, Thrift has not been consistent in their feature support and performance across all the languages, so do some research).
Protocol Buffers vs. Avro, MessagePack
While Thrift and PB differ primarily in their scope, Avro and MessagePack should really be compared in light of the more recent trends: rising popularity of dynamic languages, and JSON over XML. As most every web developers knows, JSON is now ubiquitous, and easy to parse, generate, and read, which explains its popularity. JSON also requires no schema, provides no type checking, and it is a UTF-8 based protocol - in other words, easy to work with, but not very efficient when put on the wire.
MessagePack is effectively JSON, but with efficient binary encoding. Like JSON, there is no type checking or schemas, which depending on your application can be either be a pro or a con. But, if you are already streaming JSON via an API or using it for storage, then MessagePack can be a drop-in replacement.
 Avro, on the other hand, is somewhat of a hybrid. In its scope and functionality it is close to PB and Thrift, but it was designed with dynamic languages in mind. Unlike PB and Thrift, the Avro schema is embedded directly in the header of the messages, which eliminates the need for the extra compile stage. Additionally, the schema itself is just a JSON blob - no custom parser required! By enforcing a schema Avro allows us to do data projections (read individual fields out of each record), perform type checking, and enforce the overall message structure.
Avro, on the other hand, is somewhat of a hybrid. In its scope and functionality it is close to PB and Thrift, but it was designed with dynamic languages in mind. Unlike PB and Thrift, the Avro schema is embedded directly in the header of the messages, which eliminates the need for the extra compile stage. Additionally, the schema itself is just a JSON blob - no custom parser required! By enforcing a schema Avro allows us to do data projections (read individual fields out of each record), perform type checking, and enforce the overall message structure.
"The Best" Serialization Format
Reflecting on the use of Protocol Buffers at Google and all of the above competitors it is clear that there is no one definitive, "best" option. Rather, each solution makes perfect sense in the context it was developed and hence the same logic should be applied to your own situation.
If you are looking for a battle-tested, strongly typed serialization format, then Protocol Buffers is a great choice. If you also need a variety of built-in RPC mechanisms, then Thrift is worth investigating. If you are already exchanging or working with JSON, then MessagePack is almost a drop-in optimization. And finally, if you like the strongly typed aspects, but want the flexibility of easy interoperability with dynamic languages, then Avro may be your best bet at this point in time.
2.[URL:http://qconsf.com/]
http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
This site helps me to clarify out the difference and Use case among NoSQLs.
CouchDB (V1.1.0)
- Written in: Erlang
- Main point: DB consistency, ease of use
- License: Apache
- Protocol: HTTP/REST
- Bi-directional (!) replication,
- continuous or ad-hoc,
- with conflict detection,
- thus, master-master replication. (!)
- MVCC - write operations do not block reads
- Previous versions of documents are available
- Crash-only (reliable) design
- Needs compacting from time to time
- Views: embedded map/reduce
- Formatting views: lists & shows
- Server-side document validation possible
- Authentication possible
- Real-time updates via _changes (!)
- Attachment handling
- thus, CouchApps (standalone js apps)
- jQuery library included
Best used: For accumulating, occasionally changing data, on which pre-defined queries are to be run. Places where versioning is important.
For example: CRM, CMS systems. Master-master replication is an especially interesting feature, allowing easy multi-site deployments.
Redis (V2.4)
- Written in: C/C++
- Main point: Blazing fast
- License: BSD
- Protocol: Telnet-like
- Disk-backed in-memory database,
- Currently without disk-swap (VM and Diskstore were abandoned)
- Master-slave replication
- Simple values or hash tables by keys,
- but complex operations like ZREVRANGEBYSCORE.
- INCR & co (good for rate limiting or statistics)
- Has sets (also union/diff/inter)
- Has lists (also a queue; blocking pop)
- Has hashes (objects of multiple fields)
- Sorted sets (high score table, good for range queries)
- Redis has transactions (!)
- Values can be set to expire (as in a cache)
- Pub/Sub lets one implement messaging (!)
Best used: For rapidly changing data with a foreseeable database size (should fit mostly in memory).
For example: Stock prices. Analytics. Real-time data collection. Real-time communication.
MongoDB
- Written in: C++
- Main point: Retains some friendly properties of SQL. (Query, index)
- License: AGPL (Drivers: Apache)
- Protocol: Custom, binary (BSON)
- Master/slave replication (auto failover with replica sets)
- Sharding built-in
- Queries are javascript expressions
- Run arbitrary javascript functions server-side
- Better update-in-place than CouchDB
- Uses memory mapped files for data storage
- Performance over features
- Journaling (with --journal) is best turned on
- On 32bit systems, limited to ~2.5Gb
- An empty database takes up 192Mb
- GridFS to store big data + metadata (not actually an FS)
Best used: If you need dynamic queries. If you prefer to define indexes, not map/reduce functions. If you need good performance on a big DB. If you wanted CouchDB, but your data changes too much, filling up disks.
For example: For most things that you would do with MySQL or PostgreSQL, but having predefined columns really holds you back.
Riak (V1.0)
- Written in: Erlang & C, some Javascript
- Main point: Fault tolerance
- License: Apache
- Protocol: HTTP/REST or custom binary
- Tunable trade-offs for distribution and replication (N, R, W)
- Pre- and post-commit hooks in JavaScript or Erlang, for validation and security.
- Map/reduce in JavaScript or Erlang
- Links & link walking: use it as a graph database
- Secondary indices: search in metadata
- Large object support (Luwak)
- Comes in "open source" and "enterprise" editions
- Full-text search, indexing, querying with Riak Search server (beta)
- In the process of migrating the storing backend from "Bitcask" to Google's "LevelDB"
- Masterless multi-site replication replication and SNMP monitoring are commercially licensed
Best used: If you want something Cassandra-like (Dynamo-like), but no way you're gonna deal with the bloat and complexity. If you need very good single-site scalability, availability and fault-tolerance, but you're ready to pay for multi-site replication.
For example: Point-of-sales data collection. Factory control systems. Places where even seconds of downtime hurt. Could be used as a well-update-able web server.
Membase
- Written in: Erlang & C
- Main point: Memcache compatible, but with persistence and clustering
- License: Apache 2.0
- Protocol: memcached plus extensions
- Very fast (200k+/sec) access of data by key
- Persistence to disk
- All nodes are identical (master-master replication)
- Provides memcached-style in-memory caching buckets, too
- Write de-duplication to reduce IO
- Very nice cluster-management web GUI
- Software upgrades without taking the DB offline
- Connection proxy for connection pooling and multiplexing (Moxi)
Best used: Any application where low-latency data access, high concurrency support and high availability is a requirement.
For example: Low-latency use-cases like ad targeting or highly-concurrent web apps like online gaming (e.g. Zynga).
Neo4j (V1.5M02)
- Written in: Java
- Main point: Graph database - connected data
- License: GPL, some features AGPL/commercial
- Protocol: HTTP/REST (or embedding in Java)
- Standalone, or embeddable into Java applications
- Full ACID conformity (including durable data)
- Both nodes and relationships can have metadata
- Integrated pattern-matching-based query language ("Cypher")
- Also the "Gremlin" graph traversal language can be used
- Indexing of nodes and relationships
- Nice self-contained web admin
- Advanced path-finding with multiple algorithms
- Indexing of keys and relationships
- Optimized for reads
- Has transactions (in the Java API)
- Scriptable in Groovy
- Online backup, advanced monitoring and High Availability is AGPL/commercial licensed
Best used: For graph-style, rich or complex, interconnected data. Neo4j is quite different from the others in this sense.
For example: Social relations, public transport links, road maps, network topologies.
Cassandra
- Written in: Java
- Main point: Best of BigTable and Dynamo
- License: Apache
- Protocol: Custom, binary (Thrift)
- Tunable trade-offs for distribution and replication (N, R, W)
- Querying by column, range of keys
- BigTable-like features: columns, column families
- Writes are much faster than reads (!)
- Map/reduce possible with Apache Hadoop
- I admit being a bit biased against it, because of the bloat and complexity it has partly because of Java (configuration, seeing exceptions, etc)
Best used: When you write more than you read (logging). If every component of the system must be in Java. ("No one gets fired for choosing Apache's stuff.")
For example: Banking, financial industry (though not necessarily for financial transactions, but these industries are much bigger than that.) Writes are faster than reads, so one natural niche is real time data analysis.
HBase
(With the help of ghshephard)
- Written in: Java
- Main point: Billions of rows X millions of columns
- License: Apache
- Protocol: HTTP/REST (also Thrift)
- Modeled after BigTable
- Map/reduce with Hadoop
- Query predicate push down via server side scan and get filters
- Optimizations for real time queries
- A high performance Thrift gateway
- HTTP supports XML, Protobuf, and binary
- Cascading, hive, and pig source and sink modules
- Jruby-based (JIRB) shell
- No single point of failure
- Rolling restart for configuration changes and minor upgrades
- Random access performance is like MySQL
Best used: If you're in love with BigTable. :) And when you need random, realtime read/write access to your Big Data.
example: Facebook Messaging Database (more general example coming soon)