
'Story List'에 해당되는 글 179건
- 2024.01.30 :: [Dataframe] 키 값이 같은 row가 2개 이상, 하나 row만 남기는 방법
- 2024.01.21 :: [Python] ZeroDivisionError: division by zero 처리 방법
- 2024.01.19 :: [Python] 스크립트가 동결된 실행 파일(frozen executable)이란?
- 2024.01.17 :: [QT] Main Window vs Widget application 차이
- 2024.01.12 :: [VR] UEVR, 기존게임을 VR로 전환(?)
- 2024.01.05 :: [Python] PyQt5, PyQt6 and PySide6 라이선스 설명
- 2024.01.04 :: [QT] 시그널(signal) 과 슬롯(slot)
- 2023.12.27 :: [Python] 엑셀 파일을 읽을 때 숫자 앞에 있는 어포스트로피( ' )
- 2023.11.26 :: [팁] ERROR: No matching distribution found for pythoncom 1
- 2023.10.08 :: [Python] pandas 'Unnamed: 0 column'
Pandas를 사용하여 DataFrame에서 특정 키 값이 같은 행이 두 개 이상일 때, 날짜 또는 최근 업데이트된 행만 남기는 방법은 다음과 같이 할 수 있습니다
아래와 같이 기본데이타를 보면,
data = {'key': ['A', 'B', 'A', 'B', 'C'],
'날짜': ['2024-01-01', '2024-02-01', '2024-03-01', '2024-02-15', '2024-04-01'],
'값': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
print(df)
key 날짜 값
0 A 2024-01-01 10
1 B 2024-02-01 20
2 A 2024-03-01 30
3 B 2024-02-15 40
4 C 2024-04-01 50
Key가 같은 데이타가 불규칙하게 중복되어 있습니다.
해당 데이타에서 키값을 기준으로 마지막 데이타만 추출하는 방법은 아래와 같습니다.
result_df = df.sort_values(by='날짜').drop_duplicates('key', keep='last')
print(result_df) key 날짜 값
3 B 2024-02-15 40
2 A 2024-03-01 30
4 C 2024-04-01 50
이 코드에서 sort_values 함수는 '키'를 사용하여 오름 차순(default)으로 정열합니다.
그리고, drop_duplicates 함수를 사용하여 키 열을 기준으로 중복된 행을 제거하는데, 마지막행(keep='last'을 남기게 됩니다.
추가적으로, 중복행을 제거할때, 정렬된 행의 처음 행을 남길때는 keep='first' 로 설정하면 됩니다.
ZeroDivisionError: division by zero는 주로 코드에서 어떤 값을 0으로 나누려고 할 때 발생하는 오류입니다.
이 오류를 피하는 몇 가지 방법을 아래와 같이 정리합니다.
1. 분모가 0인 경우를 확인하여 처리하기.
def ZeroDivisionError_Solve1():
divisor = 0
numerator = 10
if divisor != 0:
result = numerator / divisor
else:
result = 0 # 또는 다른 적절한 값을 할당
print(result)
2. 예외처리 사용
0으로 나누려고 할 때 ZeroDivisionError 예외가 발생하면 예외 처리 블록이 실행되어 0 또는 다른 적절한 값을 할당
def ZeroDivisionError_Solve2():
divisor = 0
numerator = 10
try:
result = numerator / divisor
except ZeroDivisionError:
result = 0 # 또는 다른 적절한 값을 할당
print(result)
3. numpy의 np.divide 함수 사용
분모가 0인 경우에 대해 예외를 발생시키지 않고, 대신 where 매개변수를 사용하여 분모가 0이 아닌 경우에만 나누기 연산
def ZeroDivisionError_Solve3():
divisor = 0
numerator = 10
result = np.divide(numerator, divisor, out=np.zeros_like(numerator), casting='unsafe',where= divisor != 0)
print(result)
4. 분모가 0인 경우에 대한 조건문 사용
각 행(row)에 대해 분모가 0이 아닌 경우에만 나누기 연산을 수행하고, 그렇지 않은 경우에는 0을 할당합니다.
def ZeroDivisionError_Solve4():
data = {'numerator': [10, 20, 30],
'divisor': [5, 0, 3]}
df = pd.DataFrame(data)
# 분모가 0이 아닌 경우에만 나누기 연산 수행
df['result'] = df.apply(lambda row: row['numerator'] / row['divisor'] if row['divisor'] != 0 else 0, axis=1)
print(df)
5. numpy의 np.where 사용
np.where를 사용하여 분모가 0이 아닌 경우에는 나누기 연산을 수행하고, 그렇지 않은 경우에는 0을 할당
def ZeroDivisionError_Solve5():
# 예제 DataFrame 생성
data = {'numerator': [10, 20, 30],
'divisor': [5, 0, 3]}
df = pd.DataFrame(data)
# np.where를 사용하여 분모가 0인 경우에 대한 처리
df['result'] = np.where(df['divisor'] != 0, df['numerator'] / df['divisor'], 0)
print(df)
[전체코드]
import numpy as np
import pandas as pd
def ZeroDivisionError_Solve1():
divisor = 0
numerator = 10
if divisor != 0:
result = numerator / divisor
else:
result = 0 # 또는 다른 적절한 값을 할당
print(result)
def ZeroDivisionError_Solve2():
divisor = 0
numerator = 10
try:
result = numerator / divisor
except ZeroDivisionError:
result = 0 # 또는 다른 적절한 값을 할당
print(result)
def ZeroDivisionError_Solve3():
divisor = 0
numerator = 10
result = np.divide(numerator, divisor, out=np.zeros_like(numerator), casting='unsafe',where= divisor != 0)
print(result)
def ZeroDivisionError_Solve4():
data = {'numerator': [10, 20, 30],
'divisor': [5, 0, 3]}
df = pd.DataFrame(data)
# 분모가 0이 아닌 경우에만 나누기 연산 수행
df['result'] = df.apply(lambda row: row['numerator'] / row['divisor'] if row['divisor'] != 0 else 0, axis=1)
print(df)
def ZeroDivisionError_Solve5():
# 예제 DataFrame 생성
data = {'numerator': [10, 20, 30],
'divisor': [5, 0, 3]}
df = pd.DataFrame(data)
# np.where를 사용하여 분모가 0인 경우에 대한 처리
df['result'] = np.where(df['divisor'] != 0, df['numerator'] / df['divisor'], 0)
print(df)
if __name__ == '__main__':
print(f'ZeroDivisionError: division by zero')
ZeroDivisionError_Solve1()
ZeroDivisionError_Solve2()
ZeroDivisionError_Solve3()
ZeroDivisionError_Solve4()
ZeroDivisionError_Solve5()PyInstaller와 같은 Python 패키징 도구를 사용하여 Python 스크립트를 독립 실행 가능한 실행 파일로 변환한 것을 의미합니다. 동결된 실행 파일은 일반적으로 사용자가 Python을 설치하지 않고도 애플리케이션을 실행할 수 있도록 만들어진 것입니다.
Python 스크립트와 해당하는 종속성들을 하나의 실행 파일로 번들로 묶어줍니다. 이로써 사용자는 Python 인터프리터나 필요한 패키지를 별도로 설치하지 않고도 애플리케이션을 실행할 수 있습니다.
동결된 실행 파일은 다음과 같은 특징을 가지고 있습니다:
- 독립성: 사용자가 별도의 Python 인터프리터나 패키지 설치 없이 애플리케이션을 실행할 수 있습니다.
- 포터빌리티: 동결된 실행 파일은 특정 플랫폼(운영체제)에 종속되지 않고, 여러 플랫폼에서 실행될 수 있도록 만들어집니다. 예를 들어, Windows에서 생성된 동결된 실행 파일은 Windows 환경에서 실행되며, macOS 또는 Linux에서 생성된 것은 각각의 환경에서 실행됩니다.
- 보안 강화: 사용자는 일반적으로 실행 파일만 받아서 실행하면 되므로, 스크립트 소스 코드나 종속성에 대한 직접적인 액세스가 어려워져 보안이 강화됩니다.
- 성능 향상: 번들로 묶인 실행 파일은 일반적으로 실행 시간에 필요한 리소스를 더 효율적으로 관리하여 성능이 향상될 수 있습니다.
스크립트가 동결된 실행 파일로 변환되면, 실행 파일이 실행될 때 PyInstaller나 유사한 도구가 _MEIPASS와 같은 메커니즘을 사용하여 애플리케이션에 필요한 리소스를 임시 디렉토리에 추출하고 실행합니다.
QT Designer를 보면 아래와 같이 선택(Main widow, Widget, Dialog 등)이 가능합니다.
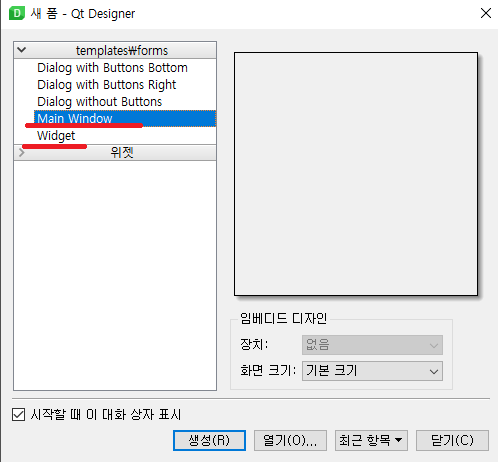
금일 , 'Main Window vs Widget application 차이'를 묻는 질문을 받으니 멍해지는 느낌이어서 간단히 정리를 하였습니다.
Qt Designer에서 Main Window와 Widget의 주요 차이점을 아래와 같이 정리하였습니다.
1. Main Window (주 창):
- 역할: 주로 어플리케이션의 메인 창을 의미합니다.
- 기능: Main Window는 일반적으로 메뉴 바, 툴바, 상태 표시줄과 같은 구성 요소들을 포함하고 있습니다.
- 구조: 주로 중앙에 중요한 작업 영역을 갖고 있고, 이 영역에 여러 위젯이나 레이아웃이 배치될 수 있습니다.
- 다양성: 여러 위젯들과 다양한 레이아웃을 포함할 수 있어서, 복잡한 어플리케이션의 구성 요소들을 효과적으로 조직할 수 있습니다.
2. Widget (위젯):
- 역할: 기본적인 UI 요소를 의미합니다.
- 종류: 버튼, 레이블, 텍스트 박스, 체크 박스 등과 같은 다양한 종류의 위젯이 있습니다.
- 사용: Main Window 내에서 주로 사용되며, Main Window의 구성 요소 중 하나로서 역할을 합니다.
- 단순성: 주로 간단한 UI 요소를 나타내며, 자주 사용되는 기본적인 UI 요소들이 여기에 속합니다.
간단히 정리하면, Qt Designer에서는 주로 Main Window를 디자인하고, 그 안에 필요한 Widget들을 배치하여 전체 어플리케이션의 사용자 인터페이스를 디자인합니다.
Release UEVR Initial Beta Release · praydog/UEVR · GitHub
Release UEVR Initial Beta Release · praydog/UEVR
It's been a long road, but we're finally here. This is the initial release of UEVR, a universal tool for enabling VR in UE4 and UE5 games. Just looking for the download? Here: https://github.com/pr...
github.com
개인적으로, 이거 진짜 혁신(?)을 뛰어넘는 게임체인저? 인데요.
기존의 언리얼 엔진 기반의 PC게임을 VR로 바로 만들어 준다.
이거 신기한게 VR로 개발되지 않은 게임도 VR로 바꿔줌.
대박이다. 전 철권을 해봤는데, 진짜 대박임.
PC게임을 VR로 하게 되다니....
개인적으로 문의를 주신 분이 있어 간단하게 설명을 드립니다.
1. PyQt5
https://choiwonwoo.tistory.com/entry/QT-%EB%9D%BC%EC%9D%B4%EC%84%A0%EC%8A%A4-%EC%A0%95%EC%B1%85
[QT] 라이선스 정책
며칠간 유니티 가격정책(https://www.asiatime.co.kr/article/20230918500098#_mobwcvr) [e와글] '가격 정책 논란'에 백기 든 유니티⋯ 개발자들은 여전히 '냉소' 유니티 테크놀러지 수수료 정책 변경 발표 유니티 "
choiwonwoo.tistory.com
결론적으로 PyQt5는 GPL과 LGPL이 혼재되어 있지만, 상업용 버젼을 개발하는데는 문제가 없습니다.
그렇지만, IOS기반의 App을 개발할때는 dynamic-linking이 지원되지 않기 때문에 문제가 될수 있습니다.
2. PyQt6 - GPL
라이선스 정책이 GPL이기 때문에 라이센스가 반드시(?)필요합니다.
만약 개발된 앱이 대박(?)을 치면 분명히 라이선스 문제가 발생함.
그래서, 상업용 버젼의 APP 개발을 생각한다면 라이선스를 구매해야 함.
3. PySide6 - LGPL
결론부터 설명을 한다면, 상업용 버젼의 APP을 개발을 생각한다면 이것을 사용하는게 맞음
dynamic-linking만 사용한다면 소스공개의 의무를 피하면서, 상업용 개발도 가능함.
4. 결론
PyQT를 사용하는 경우, PyQt5를 사용해서 개발을 진행하고 있으며, 신규 프로젝트인 경우는 PySide6를 사용하고 있음
그런데, 한가지 문제가 이전 개발 버젼(특히, 32Bit 지원...휴...)은 PySide6가 지원되지 않기 때문에, PyQt5를 사용해야함.
시그널(Signal)과 슬롯(Slot)은 Qt에서 '이벤트'를 처리하고 객체 간 통신을 쉽게 구현할 수 있도록 도와줍니다.
처음 해당 내용을 공부할때는 WINDOW MFC에서 사용되는 BEGIN_MESSAGE_MAP( theClass, baseClass) 매크로가 생각되어 살짝 공포(?)감이 생각났습니다.
(https://learn.microsoft.com/ko-kr/cpp/mfc/reference/message-map-macros-mfc?view=msvc-170)
하지만, QT의 경우는 MFC 메시지 맵에 비해 매우 직관적이고, 사용방법에 일관성이 있어 매우 쉽게 익히고 사용을 하게 해주어 매우 만족스럽네요.
1. 시그널 (Signal):
시그널은 특정 이벤트가 발생했음을 나타내는 것입니다.
예를 들어, 버튼이 클릭 또는 텍스트가 변경될 때와 같은 이벤트가 발생하면 시그널이 발생합니다.
Qt 객체, 특히 QWidget을 기반으로 하는 클래스들은 다양한 종류의 시그널을 가지고 있습니다.
2. 슬롯 (Slot):
슬롯은 시그널에 대한 반응으로 실행되는 함수나 메서드를 의미합니다.
슬롯은 사용자가 정의한 함수일 수도 있고, 이미 존재하는 함수일 수도 있습니다.
시그널과 슬롯은 1:N 또는 N:M 관계를 가질 수 있습니다.
즉, 하나의 시그널은 여러 개의 슬롯에 연결될 수 있고, 여러 개의 시그널이 하나의 슬롯에 연결될 수도 있습니다.
3, 연결 (Connection):
시그널과 슬롯을 연결하여 시그널이 발생하면 연결된 슬롯이 실행됩니다.
연결은 connect 메서드를 사용하여 설정됩니다.
시그널과 슬롯을 연결할 때, 시그널의 시그니처와 슬롯의 시그니처가 일치해야 합니다.
#include <QApplication>
#include <QPushButton>
#include <QObject>
class MyWidget : public QObject {
Q_OBJECT
public slots:
void onButtonClicked() {
qDebug() << "버튼이 클릭되었습니다.";
}
};
int main(int argc, char *argv[]) {
QApplication a(argc, argv);
QPushButton button("클릭하세요!");
MyWidget myWidget;
// 버튼의 clicked() 시그널과 myWidget의 onButtonClicked() 슬롯을 연결합니다.
QObject::connect(&button, SIGNAL(clicked()), &myWidget, SLOT(onButtonClicked()));
button.show();
return a.exec();
이 예제에서는 QPushButton의 clicked() 시그널과 MyWidget 클래스의 onButtonClicked() 슬롯을 연결하고 있습니다.
버튼이 클릭되면 시그널이 발생하고, 연결된 슬롯이 실행되어 콘솔에 메시지를 출력합니다
엑셀파일의 셀내용이 숫자인 경우 어포스트로피( ' )가 있습니다. 이경우는 해당숫자가 텍스트로 서식이 지정되었음을 의미합하고, 엑셀파일안에서 작업을 한다면 쉽게 숫자 변환을 하여 작업을 하면됩니다.
하지만, Python에서 엑셀 파일을 읽을 때 숫자 앞에 있는 아포스트로피( ' )는 숫자를 문자열로 인식하게 하므로, 숫자를 정수 또는 부동 소수점으로 변환할 때 문제가 발생합니다.
그래서 아래와 같이 어포스트로피( ' )를 제거하는 작업을 진행하여야 합니다
# 엑셀 파일 읽기
df = pd.read_excel('test.xlsx')
# 모든 열에 대해 아포스트로피 제거
df = df.map(lambda x: str(x).lstrip("'"))
pythoncom은 이름에서 짐작 할 수 있듯이, 파이썬이 윈도우 환경에서 COM(Component Object Model)을 통해 Windows 시스템의 다양한 서비스 및 기능을 사용하기 위해 사용하는 패키지입니다.
그런데, pythoncom 을 일반적(?)인 방법으로 설치를 하면 꼭 아래와 같이 에러가 발생합니다.
(mmP310_32B) C:\Users\CHOI>pip install pythoncom
ERROR: Could not find a version that satisfies the requirement pythoncom (from versions: none)
ERROR: No matching distribution found for pythoncom
pythoncom 기능을 사용하기 위해서는, 아래와 같이 해야 합니다.
(mmP310_32B) C:\Users\CHOI>conda install pywin32
그 이유는 pythoncom 모듈은 PyWin32 라이브러리에 포함되어 있기때문입니다.
개발 경험이 쌓이게 되면, 자기만의 라이브러리(?)가 샘기게 됨과 동시에 동시에 기초적인 문법등을 깜빡하게 됨을 느끼게 되네요. ㅠㅠㅠ
1. 'Unnamed: 0 column' 생성 이유
pandas를 통해 엑셀 또는 CSV 파일을 읽는 경우 ''Unnamed: 0 column' 이 생기는 경우가 발생
원인: 대상 파일(엑셀 또는 csv)에 지정된 인덱스 열이 없기 때문이다.
그래서, pandas는 default로 'Unnamed: 0'로 인덱스를 생성함
2. 'Unnamed: 0 column' 없애는 방법
df = pd.read_excel(fileName,index_col=0)파일을 읽을때, 위와 같이 명시적으로 인덱스를 명시적으로 'index_col = 0'을 설정
또는
df.drop(['Unnamed: 0'], axis=1, inplace=True)몇시적으로 컬럼을 제거해도 됩니다.
3. 결론
단순한 내용이지만, 모르면 조금 번거로운 내용이어서 정리합니다.