
'MINERVA'에 해당되는 글 97건
- 2023.04.03 :: [Panda] 두 개의 DataFrame에서 특정 열(column)을 기준으로 다른 값을 가지는 행(row)을 추출하는 방법
- 2023.03.04 :: [메모리 단위] 테라 -> 페타 -> 엑사 -> 제타 -> 요타
- 2023.02.11 :: [Python] 공백(Blank)이란? Empty or Space
- 2022.11.16 :: [Python] 두개 리스트(list)를 딕셔너리(dictionary)로 만들기
- 2022.11.15 :: [Git] 작업한 내용이 GitHub에 인식되지 않음
- 2022.11.12 :: [Python] dataframe 결합 또는 합치기 - UNION 1
- 2022.11.07 :: [Python] Dataframe 행/열 사이 누적합/누적곱
- 2022.10.15 :: [Kiwoom API] OpenAPI OCX 업데이트 에러.. 1
- 2022.09.11 :: [libevent] visual studio 2019 compile
- 2022.09.03 :: [Python] 동적 변수 선언, 값 할당 그리고 사용
dataframe의 row와 column 수가 같다면, compare등의 함수를 사용하여 쉽게 되는데, row수가 다른 경우는 이 방법이 최선듯하여 공유 합니다.
간단하게 예제 코드를 기록하였습니다.
import pandas as pd
# 첫 번째 DataFrame 생성
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
# 두 번째 DataFrame 생성
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': [5, 6, 7, 8]})
# 두 개의 DataFrame을 key 열을 기준으로 merge
merged = pd.merge(df1, df2, on='key', how='outer', suffixes=('_left', '_right'))
# value_left 열과 value_right 열이 다른 행을 추출
diff_rows = merged[merged['value_left'] != merged['value_right']]
print(diff_rows)
오늘 추가적인 스토리지가 필요하여 용량을 확인하다가, 격세지감(?)이 느껴져 기록으로 남기게 됨.
정말 빠르게 발전(?)하는게 느껴진다.
얼마전(?)만 해도, 기가만 되도 와~~했던거 같은데....
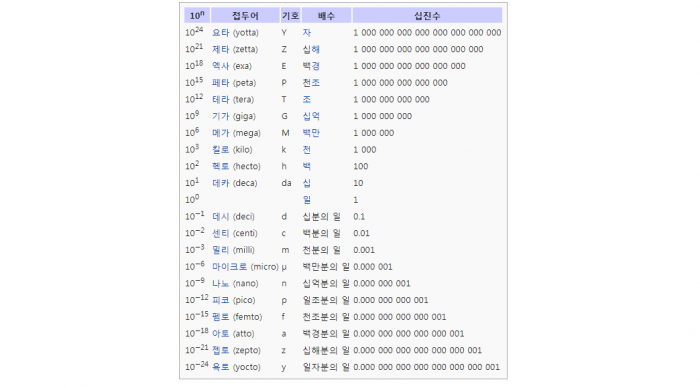
메모리 단위 발전
1 Bit -> 1 Byte -> 1 K Byte -> 1 M Byte -> 1G Byte -> 1T Byte -> 1P Byte -> 1E Byte -> 1Z Bpyte -> 1Y Byte
프로그램 테스트를 진행 하다가 예상치 못한 동작이 발견되어, 원인을 파악해 보니, 공백 처리가 미진하게 되어 발생되었음을 확인하게되었습니다. 이 이슈는 정말 아주 아주 오랜(?)만에 경험하게 되었습니다.
공백(Blank)는 두가지 의미로 생각해야 합니다.
진짜 아무것도 없다? 아니면, 화면에 보이지 않는 어떤 값이 있는건지?
간단히 생각의 흐름대로 아래와 같이 정리하여 보았습니다.
1. 예제 데이타
- 기대한 데이타: 값이 없는 경우(ex: 공백 등) 모두 0으로 설정( dataframe = dataframe.fillna(0))
- 예상치 못한 데이타: 아래와 같이 0으로 변경되지 않고 빵구(?), 정체 불명의 공백이 그대로 있음
저 공백에는 머가 있는거지?
아이템 경험가중치
0 0
1 0
2 0
: :
60 0
61 0
62
63
64 0
65 0
66
67
68 0
: :
: :
106 0
107 0
108 0
109
110 0
111
112 0
: :
127 6,243,841
128 23,787,440
129 11,598,306
130 5,240,070
131 5,933,144
: :
: :2. 빵구(?) 정체 확인
2.1 접근1
- 아래와 같이 null 이 있는지 확인
print(expDf.info())
print(expDf.isnull())RangeIndex: 2690 entries, 0 to 2689
Data columns (total 1 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 경험가중치 2690 non-null object
dtypes: object(1)
memory usage: 21.1+ KB
None
경험가중치
0 False
1 False
2 False
3 False
4 False
: :
: :
2688 False
2689 False- 위와 같이, 공백이 없다는 것을 확인함.
2.2 접근2
- 각 컬럼 값의 길이를 찍어 봄
print(expDf['경험가중치'].str.len())0 NaN
1 NaN
: :
61 NaN
62 2.0
63 2.0
64 NaN
65 NaN
66 2.0
67 2.0
68 NaN
: :
: :
108 NaN
109 2.0
110 NaN
111 2.0
112 NaN
: :
124 NaN
125 NaN
126 NaN
127 10.0
: :
2688 11.0
2689 11.0- 길이를 확인하여 보니, 어떤 값이 들어 가 있다는 것을 확신하게 됨
2.3 접근3
- 해당 행(62번행) hex값을 확인함
print(expDf['경험가중치'].iloc[62])
print(type(expDf['경험가중치'].iloc[61]))
print(type(expDf['경험가중치'].iloc[62]))
# str -> hex
# value = ''.join(format(ord(i), '08b') for i in expDf['경험가중치'].iloc[62])
#print(str(value))
print(expDf['경험가중치'].iloc[62].encode('utf-8').hex())<class 'int'>
<class 'str'>
c2a020- 값을 확인해 보면, 62번 행은 string 타입이고, 이 값의 hex값을 위와 같이 확인할수 있다.
그리고, hex값 20은 SPACE를 의미 한다는 것을 확인할수 있게 됨
3. 해결방법
- 원인 확인: 해당 공백이 SPACE에 의해서 발생했음을 확인함.
expDf['경험가중치'] = expDf['경험가중치'].replace(r'^\s+$', np.nan, regex=True)
expDf['경험가중치'] = expDf['경험가중치'].replace(np.nan, 0)- 'SPACE' 공백을 NaN으로 전환하고, 이 값을 0으로 바꿈
아이템 경험가중치
: :
59 0
60 0
61 0
62 0
63 0
64 0
65 0
66 0
67 0
: :정상적으로 결과를 나왔음을 확인
4. 결과
- NULL관련된 이슈는 참으로 오래된 이슈(?)여서 재밌기도 하였지만, 느닷없이 발생했을때는 좀 놀랐네요.
개발을 진행하다 보면, 두개의 리스트중 하나를 key로 하고, 나머지 하나의 리스트를 value 연결합니다.
이때, C++/Java/c#등의 언어 map을 사용하고, Python은 dictionary를 사용하게 됩니다.
Python은 다른언어에 비교해서 문법적으로 매우 직관적입니다. 대신, 다른 언어와 다르게 zip()함수를 사용합니다.
[코드예제]
keyList = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
valueList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pairDic = {key: value for key, value in zip(keyList,valueList)}
print(pairDic)
print(pairDic['j'])
print(pairDic['e'])[코드결과]
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': 7, 'h': 8, 'i': 9, 'j': 10}
10
5
프로젝트를 진행하다가, 특정 파일이 내 로컬 pc에만 있고, Git으로 업데이트가 반영되지 않는 경우가 있음.
나의 경우 GUI GitHub Desktop을 사용하지만, 이런경우 command 환경으로 돌아가서 아래와 같이 실행함
[실행]
> git add '파일명'
D:\NextTime>git add MMF.txt
The following paths are ignored by one of your .gitignore files:
MMF.txt
hint: Use -f if you really want to add them.
hint: Turn this message off by running
hint: "git config advice.addIgnoredFile false"
해당 내용을 보면, 파일이 예외처리되었다는 의미임
> git add -f '파일명'
D:\NextTime\cwwFactory\매일마다\12월>git add -f MMF.txt
[결과]
정상적으로 파일이 github에 인식되어 git에 반영완료
행(row)과 열(column) 형태인 datafram을 결합하기 위해서 concat() 함수를 사용합니다.
사용 방법은 매우 직관적이며 아래의 샘플코드를 한번 보시면 고등학생때 수업시간에 배운 집합을 생각하시면 매우 간단합니다.
1. 예제1
SampleDf1 = {'A': ['A1', 'A2', 'A3', 'A4'],
'B': ['B1', 'B2', 'B3', 'B4'],
'C': ['C1', 'C2', 'C3', 'C4'],
}
df1 = pd.DataFrame(SampleDf1)
print(df1)
SampleDf2 = {'A': ['A1', 'A2', 'A3', 'A4'],
'B': ['B1', 'B2', 'B3', 'B4'],
'C': ['C1', 'C2', 'C3', 'C4'],
}
df2 = pd.DataFrame(SampleDf2)
print(df2)(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
unionDf = pd.concat([df1, df2])(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
unionDf = pd.concat([df1, df2], ignore_index=True)- 인덱스 새롭게 설정함
(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
4 A1 B1 C1
5 A2 B2 C2
6 A3 B3 C3
7 A4 B4 C4
unionDf = pd.concat([df1, df2],axis=1)
print(unionDf)- 옆으로 데이타를 연결
(실행결과)
A B C A B C
0 A1 B1 C1 A1 B1 C1
1 A2 B2 C2 A2 B2 C2
2 A3 B3 C3 A3 B3 C3
3 A4 B4 C4 A4 B4 C4
unionDf = pd.concat([df1,df2],ignore_index=True).drop_duplicates(keep='first')
print(unionDf)# 중복행 제거: drop_duplicates() 사용
(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
unionDf = pd.concat([df1,df2],ignore_index=True).drop_duplicates(keep='last')
print(unionDf)(실행결과)
A B C
4 A1 B1 C1
5 A2 B2 C2
6 A3 B3 C3
7 A4 B4 C4
2. 예제2
SampleDf1 = {'A': ['A1', 'A2', 'A3', 'A4'],
'B': ['B1', 'B2', 'B3', 'B4'],
'C': ['C1', 'C2', 'C3', 'C4'],
}
df1 = pd.DataFrame(SampleDf1)
print(df1)
SampleDf2 = {'C': ['C1', 'C2', 'C3', 'C4'],
'D': ['D1', 'D2', 'D3', 'D4'],
'E': ['E1', 'E2', 'E3', 'E4'],
'F': ['F1', 'F2', 'F3', 'F4'],
}
df2 = pd.DataFrame(SampleDf2)
print(df2)
unionDf = pd.concat([df1, df2])
print(unionDf)(실행결과)
A B C
0 A1 B1 C1
1 A2 B2 C2
2 A3 B3 C3
3 A4 B4 C4
C D E F
0 C1 D1 E1 F1
1 C2 D2 E2 F2
2 C3 D3 E3 F3
3 C4 D4 E4 F4
A B C D E F
0 A1 B1 C1 NaN NaN NaN
1 A2 B2 C2 NaN NaN NaN
2 A3 B3 C3 NaN NaN NaN
3 A4 B4 C4 NaN NaN NaN
0 NaN NaN C1 D1 E1 F1
1 NaN NaN C2 D2 E2 F2
2 NaN NaN C3 D3 E3 F3
3 NaN NaN C4 D4 E4 F4
unionDf = pd.concat([df1, df2], ignore_index=True)
print(unionDf)(실행결과)
A B C D E F
0 A1 B1 C1 NaN NaN NaN
1 A2 B2 C2 NaN NaN NaN
2 A3 B3 C3 NaN NaN NaN
3 A4 B4 C4 NaN NaN NaN
4 NaN NaN C1 D1 E1 F1
5 NaN NaN C2 D2 E2 F2
6 NaN NaN C3 D3 E3 F3
7 NaN NaN C4 D4 E4 F4
unionDf = pd.concat([df1, df2],axis=1)
print(unionDf)(실행결과)
A B C C D E F
0 A1 B1 C1 C1 D1 E1 F1
1 A2 B2 C2 C2 D2 E2 F2
2 A3 B3 C3 C3 D3 E3 F3
3 A4 B4 C4 C4 D4 E4 F4
3.정리
세부적인 설명보다는 샘플코드와 실행결과를 보면 이해가 쉽게 될것으로 생각되어 코드와 실행결과를 남겼습니다.
Dataframe 객체를 추출(?)이후, 정보 흐름 파악을 위해 컬럼 또는 로우간 누적 합/곱을 합니다.
이때 사용하는 함수로 cumsum / cumprod
가 있습니다.
위에서부터 아래로 한줄씩 덧셈/곱셈을 누적합니다.
1. 예제 데이타 프레임
df = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]}, index=['1', '2', '3'])
print(df)[결과]
A B C
1 1 4 7
2 2 5 8
3 3 6 9
2. 누적합 예제
############################
# 행누적합
print()
print(df.cumsum(axis=1))
# 열누적합
print()
print(df.cumsum(axis=0))[결과]
A B C
1 1 5 12
2 2 7 15
3 3 9 18
A B C
1 1 4 7
2 3 9 15
3 6 15 24
3. 누적곱 예제
############################
# 행누적곱
print()
print(df.cumprod(axis=1))
# 열누적곱
print()
print(df.cumprod(axis=0))
[결과]
A B C
1 1 4 28
2 2 10 80
3 3 18 162
A B C
1 1 4 7
2 2 20 56
3 6 120 504
4. 정리
개발 언어중에, 위의 기능은 python dataframe에만 있는것으로 알고 있다.
C/C++, Java등에서 해당 기능을 구현할려면 루핑을 돌려서 처리하였는데, 역시 Python은 데이타 분석을 위한 다양한 기능이 기본으로 제공되는 것 같다.
참여했던 프로젝트를 완료하고 시간이 지난후에 어떤 기능이 않된다고 연락을 받을때 마다 순간 순간 멍해진다.
오늘도 프로그램이 뜨지 않는다고 해서 연락을 받고 들여다 보니 쩝....
그래도 간략히 정리해두자.

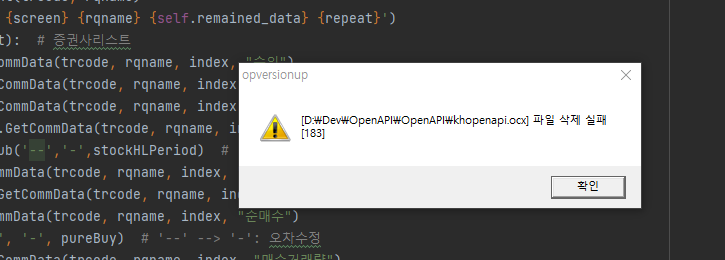
해당 화면이 뜨는 원인은 분명하다. kiwoom에서 패포하는 ocx 파일의 버젼이 갱신, 즉 업데이트되었기 때문입니다.
그래서, 업데이트를 해주어야 하는데, 현재 프로젝트에서 직접 kiwoom에서 패포하는 ocx파일을 가져올수 없습니다.
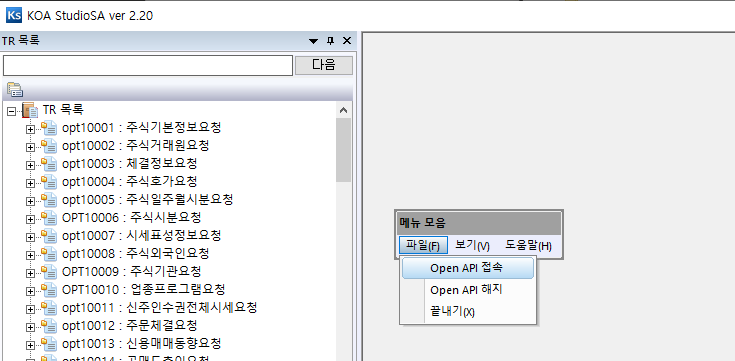
그래서, kiwoom에서 관리 배포하는 KOA StudioSA를 로긴을 정상적으로 진행하는 방식으로 OCX를 업데이트 하면 해결됩니다.
참 쉽죠~~
몇년전 libevent library기반으로 개발된 프로젝트를 업그레이드중 libevent를 visual sutdio 2019 포팅하는게 조금 번거로워 해당 내용을 정리합니다.
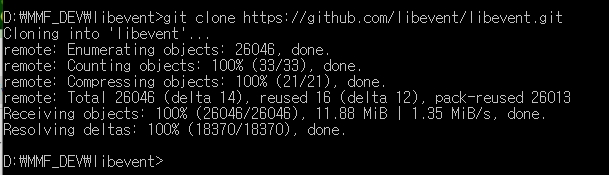
1. 소스 가져오기
> git clone https://github.com/libevent/libevent.git
2. 컴파일 하기
1) 빌드 디렉토리 생성
> md build
2) cmake-gui.exe 실행 및 path 설정
-(1) 소스 파일과 빌드 target 디렉토리 설정
-(2) 설정(configure) 파일 생성
-(3) visual studio 2019 solution 파일 생성
-(4) 빌드하기
(1) 소스 파일과 빌드 target 디렉토리 설정
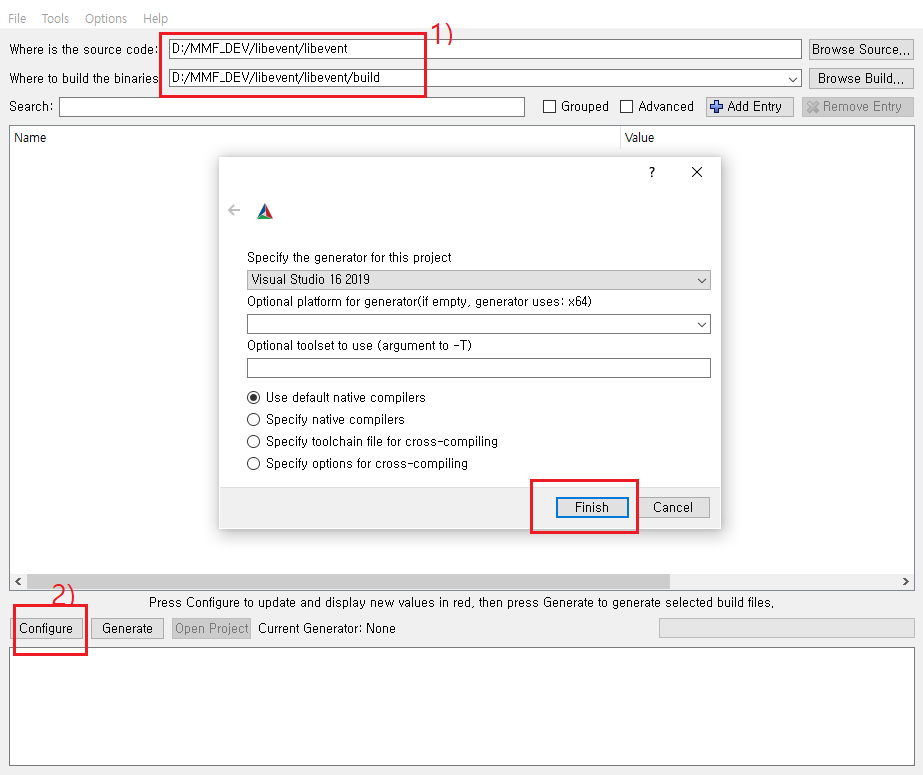


# 위 에러 메시지를 보면, OpenSSL 라이브러리에 대한 설정내용이 없기때문임.
해결방법은 OpenSSL 라이브러리를 설정해주거나, 아니면 빼버리면 됩니다.(전, 빼는 방향으로 진행하겠습니다.^^)
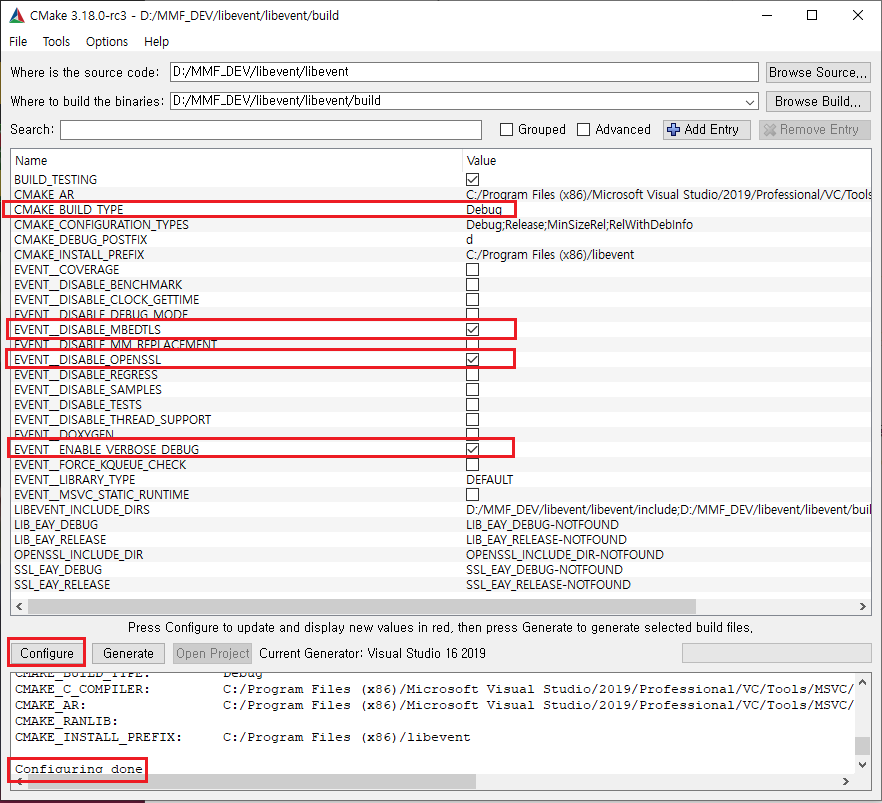
# BUILD_TYPE을 Debug, 암호모듈(MBEDTLS,OPENSSL)을 OFF, 그리고 빌드정보를 보기 위해 VERBOSE로 설정
(2) Configure를 클릭하면, 위와 같이 성공 메시지를 확인 가능
> Configuring done
(3) visual studio 2019 solution 파일 생성
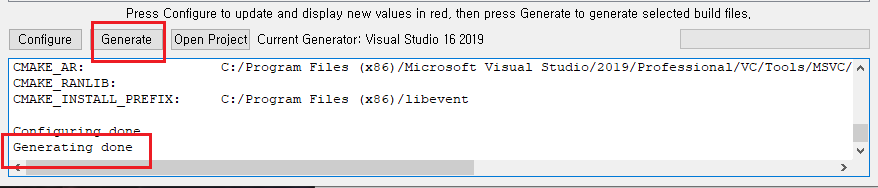
(4) 빌드하기
# Open Project를 클릭 -> Visual Studio 2019 오픈
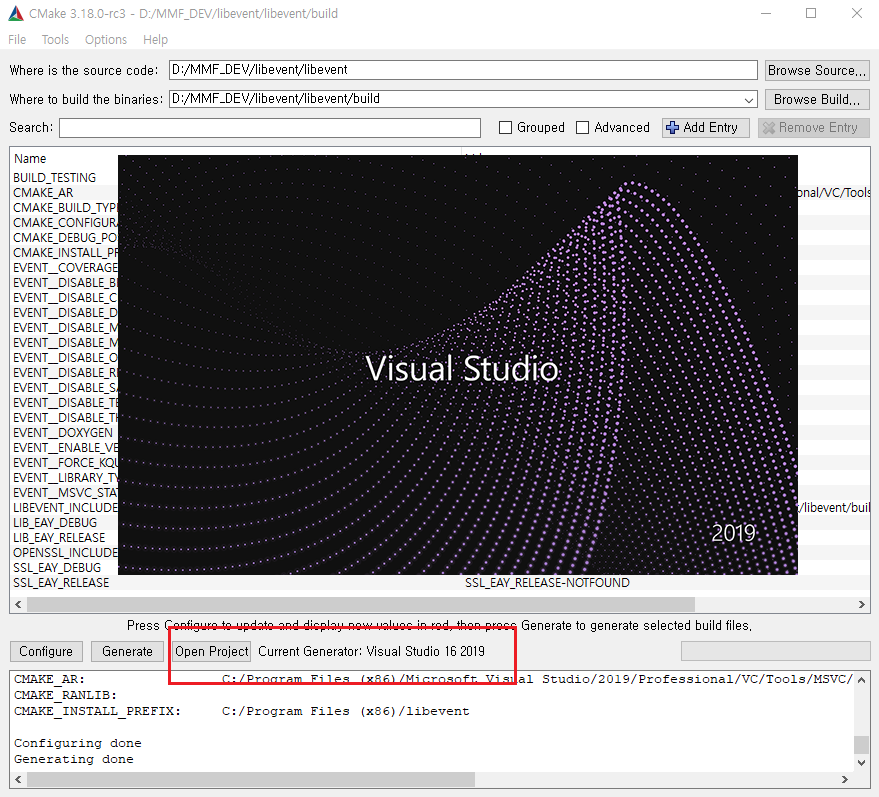
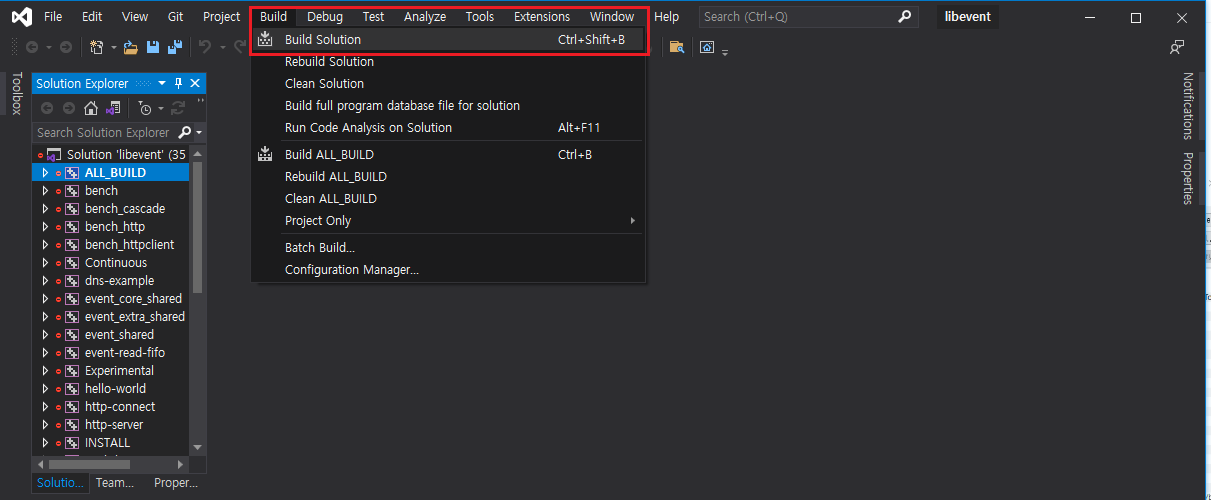
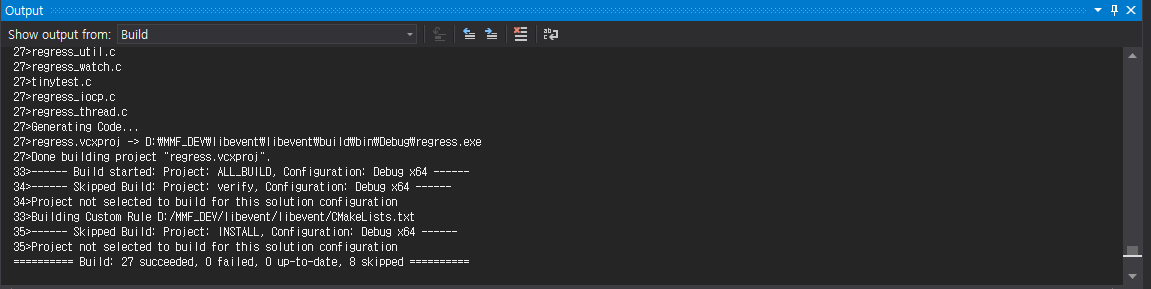
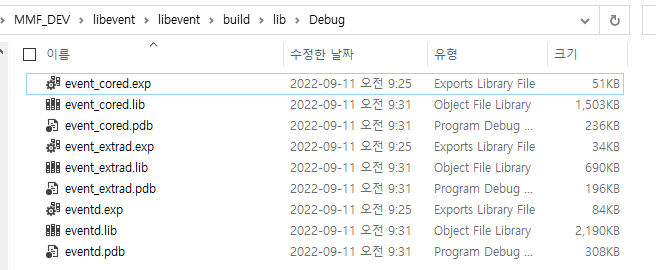
# 빌등 완료후 생성된 라이브러 확인
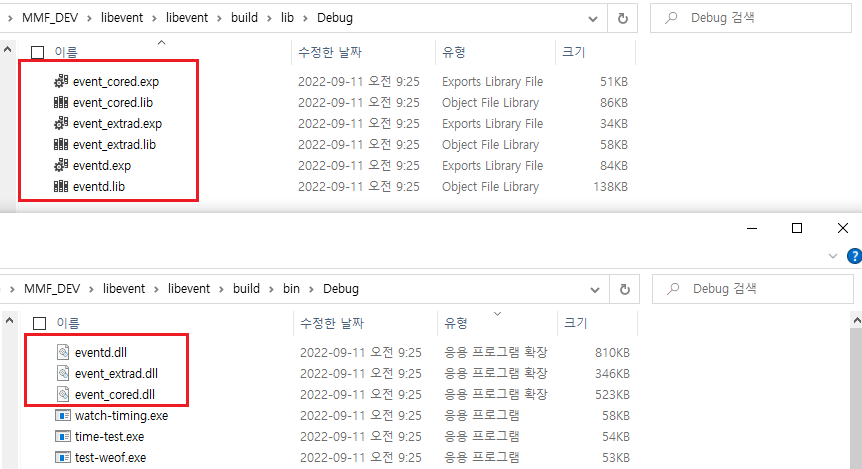
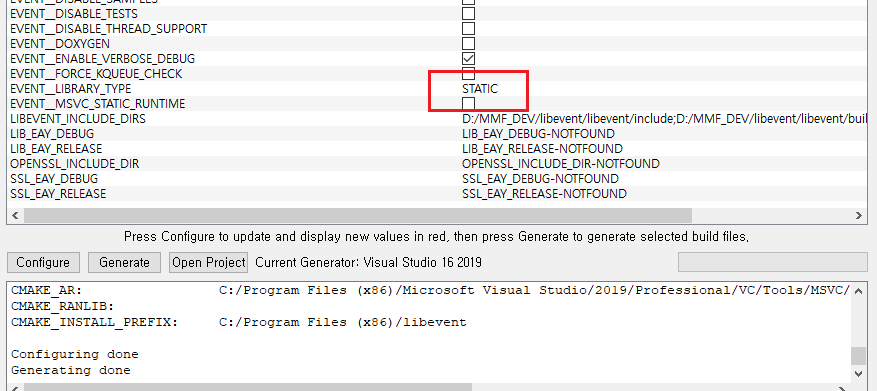
cf) 참고로 static library를 생성을 위해서, LIBRARY_TYPE을 STATIC으로 변경하면됨
C/C++을 오랫동안(음...20년이 넘나?)사용하다가, Data type assignment 언어인 Python은 처음부터 접근과 사용이 매우 수월(?)했습니다. 그렇지만, 문법(?)적으로 동적으로 변수를 선언 및 사용하는 방법은 다른 개발 언어와 비교했을때 확실히 다름(?)이 있어, 아래와 같이 간단히 정리하고자 합니다.
# 지역별 APT 평균 가격
# 강남구,서초구,........
regionPrice = ['14억', '13억', '9억', '7억', '6억']
#regionMajor = [....]
# 동적 변수 선언 및 값 할당
for i in range(0, len(regionPrice)):
locals()['df{}'.format(i)] = regionPrice[i]
# 동적 변수 접근
for i in range(0, len(regionPrice)):
df = locals()['df{}'.format(i)]
print(df)프로젝트에 사용된 일부 코드를 발취하여 편집하였습니다.
글로벌 변수로 사용하기 위해서는 locals() --> Globals()로 변경하면 됩니다.
기술적인 이론을 이해하기 위해서는, Python의 메모리 관리와 인터프린터 언어의 특성에 대해서 감(?)을 잡아함. 이부분은시간이 날때 따로 정리 하도록하겠습니다.